Впервые я изучил Kubernetes (сокращенно «k8s») в 2018 году, когда мой менеджер усадил меня и сказал: «Cloudflare мигрирует на Kubernetes, и вы занимаетесь миграцией нашей команды». Меня это немного пугало, потому что я был хорошим программистом и посредственным инженером. Я знал, как писать код, но не знал, как его развертывать или контролировать в продакшене. Моя степень в области компьютерных наук научила меня всему, что касается алгоритмов, структур данных, систем типов и операционных систем. Он не научил меня ни контейнерам, ни ElasticSearch, ни Kubernetes. Я не думаю, что за всю свою степень написал ни одного файла YAML. Я боялся оп. Я был в ужасе от Kubernetes.
В конце концов я справился и перенес всю инфраструктуру Cloudflare Tunnel с Marathon на Kubernetes. Мне это не нравилось, и я сильно просрочил свой дедлайн, но я многому научился. Сейчас 2022 год, и я возглавляю небольшую команду инженеров, некоторые из которых никогда раньше не использовали Kubernetes. Так что я обнаружил, что объясняю им Kubernetes. Они, похоже, сочли это полезным, поэтому я решил записать его и поделиться им с остальными из вас.
Эта статья предназначена для инженеров, которым необходимо развернуть свой код с помощью Kubernetes, но которые понятия не имеют, что такое Kubernetes и как он работает. Я собираюсь рассказать вам историю о младшем инженере. Мы будем следовать за этим инженером, пока он создает высококачественный сервис, и когда у него возникнут проблемы, мы увидим, как Kubernetes может помочь их решить. Надеюсь, это поможет вам создавать свои собственные сервисы в k8s!
Contents
- 1 Введение: зачем использовать k8s?
- 2 Решение проблем с Kubernetes
- 2.1 Проблема: я хочу запустить контейнер
- 2.2 Проблема: что делает мой модуль?
- 2.3 Проблема: я хочу, чтобы мой контейнер перезапускался при сбое.
- 2.4 Проблема: у моего контейнера никогда не должно быть простоев, даже если он выйдет из строя.
- 2.5 Проблема: мой контейнер не справляется с объемом получаемого трафика.
- 2.6 Проблема: мне нужно развернуть новую версию моего бэкенда, не вызывая простоя
- 2.7 Проблема: мне нужно направить трафик на все модули в развертывании.
- 2.8 Проблема: балансировка нагрузки между подами
- 2.9 Проблема: я хочу принимать трафик из-за пределов кластера
- 2.10 Проблема: я хочу ограничить сеть внутри кластера
- 2.11 Проблема: я хочу использовать HTTP/S вне кластера и HTTP внутри кластера
- 2.12 Проблема: я хочу получить метрики о моем сервисе
- 2.13 Проблема: мне нужна изоляция от других проектов, использующих тот же кластер
- 3 Вывод
Введение: зачем использовать k8s?
Какую проблему k8s вообще пытается решить? Зачем нам еще одна новая сложная программная система со своими странными именами собственными, схемами YAML и процессом сертификации? Я отвечу на этот вопрос, но прежде чем я это сделаю, нам нужно сделать быстрый шаг назад и вернуться в 2013 год, когда индустрия программного обеспечения впервые стала одержима:
Контейнеры
Допустим, вы хотите развернуть два сервера Python. Одному из них нужен Python 3.4, а другому — Python 3.5. Как их развернуть на одной машине? Вы можете взломать сценарий оболочки вместе, возможно, использовать инструменты, специфичные для Python, такие как venv . Хорошо, это работает. Но это не очень хорошо масштабируется, когда вы начинаете развертывать десятки сервисов Python, особенно потому, что у вас возникают аналогичные проблемы с Node, Ruby или всеми другими языками, которые вы используете.
Вместо этого вы запускаете каждый сервер Python в своем собственном контейнере . Контейнер, как и виртуальная машина, позволяет вашей службе действовать так, как будто это единственная служба на этой машине. Он получает собственную чистую файловую систему, и теперь вам не нужно беспокоиться о конфликтах с другими зависимостями. Большой!
Большое преимущество контейнеров перед виртуальными машинами заключается в том, что они очень легкие. На одной машине можно запускать гораздо больше контейнеров , чем на виртуальных машинах. Почему? Потому что каждая виртуальная машина должна устанавливать свою собственную ОС, но контейнеры могут использовать одну и ту же базовую ОС.
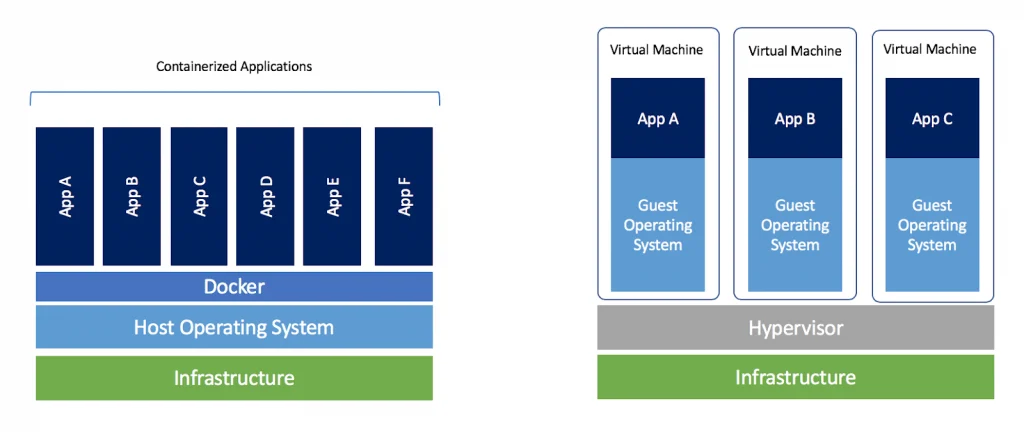
Чтобы узнать больше о контейнерах для начинающих, прочитайте этот .
Теперь вы можете развернуть все свои сервисы на одном компьютере, каждый со своим контейнером, в полной изоляции. Они никак не могут мешать друг другу. Это здорово , пока вы не поймете, что вашим службам действительно иногда нужно общаться друг с другом. Оказывается, позволить процессам обмениваться сообщениями — довольно распространенная вещь, и она имеет решающее значение для вашей работы .. Ваша компания, вероятно, использует сервис-ориентированную архитектуру или, возможно, микросервисы, но в любом случае, вероятно, есть несколько сервисов, которым необходимо обмениваться данными для обработки запросов. Например, внешние интерфейсы, серверные части, балансировщики нагрузки, управление сеансами, аутентификация, права пользователей, ведение журналов и выставление счетов могут быть отдельными службами, которым необходимо взаимодействовать. Если вы поместите все эти сервисы в контейнер, вы сделаете невозможным их координацию — по замыслу.
Оркестрация контейнеров
Блин! У нас есть проблемы. Используя контейнеры, мы построили для каждой службы идеальную маленькую изолированную ячейку, чтобы они не могли обмениваться данными. Но мы слишком хорошо выполнили свою работу, нам действительно нужно, чтобы они общались. Но только определенными способами, которые выбираете вы, программист. Мы не хотим возвращаться к временам, когда еще не было контейнеров, когда все программы делились всем — мы видели, какой беспорядок это создает.
Другая проблема, с которой вы столкнетесь, заключается в том, какие контейнеры следует запускать в первую очередь . Допустим, в вашей компании есть система непрерывной интеграции , которая запускается каждый раз, когда вы объединяете PR с master. Вы можете использовать его для создания нового образа контейнера для каждой фиксации в вашей кодовой базе, упаковки вашего кода и всех его зависимостей (например, библиотек для связывания или конкретной версии Python). Теперь, если ваша фиксация изменяет зависимости кода, образ контейнера этой фиксации будет иметь правильную комбинацию кода и зависимостей. Но теперь у вас есть все эти сотни или тысячи контейнеров. Как вы сообщаете своим серверам, какие контейнеры запускать?
Мы решаем эту проблему с помощью программы оркестрации контейнеров , которая выборочно включает некоторые контейнеры и предоставляет им некоторые ресурсы, включая «связь с другими контейнерами». Фраза «контейнерная оркестровка» — это метафора оркестра. Представьте, если бы музыканты в оркестре не слышали друг друга. Они будут играть с разной скоростью, трубы заглушат гобои, каждый скрипач будет считать себя солистом, и ни один из них не будет играть гармонические партии. Это был бы хаос. Чтобы превратить этот беспорядок из изолированных музыкантов в оркестр, вам нужна структура , а для обеспечения соблюдения структуры вам нужен хороший дирижер.
Программа оркестрации контейнеров позволяет:
- Выберите, какие контейнеры должны запускаться
- Сколько копий каждого контейнера должно работать
- Каким контейнерам разрешено совместно использовать ресурсы, такие как тома, каталоги, файлы или сети.
- Выберите, какие контейнеры могут получить доступ к одним и тем же портам и хостам для совместной работы в сети.
Контейнеры решают проблему «как мне остановить эти сервисы, мешающие друг другу». Оркестрация контейнеров решает, «как я могу позволить этим службам работать вместе». Они также решают, «какие службы должны работать».
Существует множество различных конкурирующих инструментов оркестровки. Возможно, вы использовали Docker Compose , он прост и встроен в Docker, самый популярный движок контейнеров 1 . Если вам нужно запускать контейнеры только на одном физическом компьютере, я бы посоветовал использовать Docker Compose. Но, конечно же, современные компании-разработчики программного обеспечения никогда не развертывают программное обеспечение только на одной машине. Во-первых, эта единственная машина, вероятно, не может обрабатывать весь ваш трафик. Во- вторых, даже если бы это было возможно , это была бы единственная точка отказа — если эта машина выйдет из строя, ваши услуги станут недоступны, ваши клиенты не смогут размещать заказы, и вы потеряете деньги. Таким образом, инженерам в реальном мире необходимо организовывать контейнеры на множестве различных физических серверов.
Когда я присоединился к Cloudflare, мы использовали для этого Apache Marathon , но быстро мигрировали на Kubernetes. Это привело к одному большому вопросу:
Почему кубернет?
Kubernetes существует для решения одной проблемы: как запустить m контейнеров на n серверах?
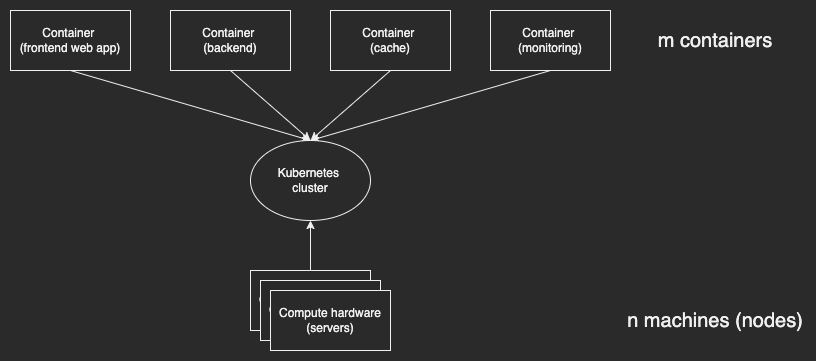
Ее решением является кластер . Кластер Kubernetes — это абстракция. Это большой абстрактный виртуальный компьютер со своим собственным виртуальным стеком IP, сетью, диском, оперативной памятью и процессором. Он позволяет развертывать контейнеры так, как если бы вы развертывали их на одном компьютере, на котором больше ничего не запущено. Кластеры абстрагируются от различных физических машин, на которых работает кластер.
Кластер работает на ваших n серверах. Сервер, являющийся частью кластера Kubernetes, называется узлом .
Хорошая абстракция должна скрывать от вас детали, но давать вам доступ к этим деталям, если вам это действительно необходимо. Как правило, ваши контейнеры не знают, и им все равно, на каком узле они работают — абстракция кластера достаточно хороша. Но если вам действительно нужно, вы можете запросить и проверить различные узлы, составляющие кластер.
У вашей компании может быть один кластер Kubernetes или их может быть много. На определенном уровне масштаба вам может понадобиться несколько кластеров — может быть, один кластер для производства и один для промежуточной обработки, или по одному кластеру в Америке, Европе и Азии. Ваша команда SRE или платформы, вероятно, сообщит вам, в какой кластер следует выполнить развертывание.
Итак, зачем использовать Kubernetes?
- Вы хотите использовать контейнеры, чтобы развертывать свои службы изолированно друг от друга.
- Вы хотите использовать оркестратор контейнеров для управления развертыванием контейнеров и совместным использованием ресурсов между ними.
- Если вы работаете на одной машине, просто используйте Docker Compose.
- Если вы работаете на многих машинах, которые могут включаться и выключаться, и вам необходимо запланировать свои контейнеры на них, используйте Kubernetes.
Решение проблем с Kubernetes
Я собираюсь рассказать вам о различных проблемах, с которыми может столкнуться типичный инженер-программист, пытаясь запустить новую, масштабируемую, отказоустойчивую и высокодоступную веб-службу. Мы рассмотрим стандартные решения этих проблем и способы их решения в Kubernetes. К тому времени, когда вы закончите это, вы, надеюсь, будете знать достаточно, чтобы k8s работало продуктивно.
Кстати, всякий раз, когда я использую слово с заглавной буквы, превращая его в имя собственное, это потому, что оно имеет особое значение в мире k8s, например, Pod или Service. Я дам ссылку на документы для этой концепции при первом использовании.
Проблема: я хочу запустить контейнер
Начнем с простого. Вы работали над проектом с кодовым названием kangaroo, и он готов к развертыванию. Итак, вы создаете образ контейнера для его запуска: kangaroo-backend. На вашем рабочем месте их службы работают в кластере Kubernetes, поэтому вам необходимо развернуть этот контейнер в кластере. Как? Вам нужно определить Kubernetes Pod . Под — это набор из одного или нескольких контейнеров (обычно только один контейнер, хотя и 2 ). Поды — это минимальная единица развертывания в Kubernetes. Это самая простая и маленькая вещь, которую вы можете развернуть в k8s. Итак, давайте определим под, который запускает наш контейнер, например:
apiVersion: v1
kind: Pod
metadata:
name: kangaroo-backend
spec:
containers:
- name: kangaroo-backend
image: kangaroo-backend:1.14.2
ports:
- containerPort: 80
Этот YAML определяет новый ресурс k8s, который вы можете развернуть в своем кластере. Все ресурсы, независимо от того, что вы развертываете, имеют четыре свойства:
- apiVersion: какую версию определения ресурса k8s использовать. Определения ресурсов (например, Pod) имеют версию, поэтому комитет Kubernetes может позже изменить определение, не нарушая работу всех, кто использует старую версию. Когда вы пишете API, вы, вероятно, включаете «v1» в начале на тот случай, если позже вам понадобится внести обратно несовместимое изменение. Что ж, комитет Kubernetes делает то же самое.
- kind: все ресурсы относятся к определенному типу — в данном случае Pod.
- метаданные: пары ключ-значение, которые можно использовать для запроса и организации ресурсов в кластере.
- spec: Подробная информация о том, что вы развертываете. У каждого сорта есть спец. Например, ресурс типа Pod должен иметь
containersключ с массивом контейнеров, каждый из которых имеет файлimage.
Мы развертываем модуль, который представляет собой один или несколько контейнеров (обычно только один), поэтому мы установили kind: Podи должны предоставить правильный файл spec. Здесь наша спецификация говорит, что мы запускаем один контейнер, изображение kangaroo-backend:1.14.2. Мы также сообщаем Kubernetes, что контейнер будет прослушивать порт 80.
ХОРОШО! Если мы сохраним это, поскольку pod.yamlмы можем развернуть его, запустив kubectl apply -f pod.yaml. Поздравляем, вы только что развернули контейнер в своем кластере k8s.
Проблема: что делает мой модуль?
Итак, вы развернули модуль. ХОРОШО. Это работает? Делает ли он то, что вы от него ожидаете?
Вы можете использовать kubectlдля проверки вашего модуля. Во- первых, я предлагаю использовать псевдоним kubectlв kвашем терминале, потому что вы будете его часто использовать. Вы можете выполнить запуск k get pods, чтобы просмотреть список развернутых вами модулей и получить k describe pod <ID>дополнительную информацию об этом модуле. Если ваш модуль регистрируется в stdout/stderr, используйте k logs <ID>для просмотра журналов модуля. Если вы действительно не уверены в поде, вы можете подключиться к нему по SSH, запустив k exec <pod ID> -it -- /bin/bash. Дополнительные советы, подобные этому, можно найти на странице Kubernetes Debug Running Pods .
Проблема: я хочу, чтобы мой контейнер перезапускался при сбое.
Project Kangaroo идет хорошо, но каждые несколько дней происходит сбой. Это важная служба, поэтому ее всегда следует перезапускать при сбое. Если бы это был обычный процесс Linux на обычном сервере Linux, вы могли бы использовать сценарий оболочки для его перезапуска или, возможно, systemd. Но как обеспечить автоматический перезапуск модуля k8s?
Вот где проявляется большая сила k8s: k8s является декларативным, а не императивным . Вы заявляете , что там должен работать этот pod, и если это когда-нибудь не так, Kubernetes это исправит. Таким образом, если модуль выходит из строя, Kubernetes перезапустит его, потому что это возвращает состояние кластера в соответствие с предполагаемым состоянием, которое вы указали в манифесте. Вы можете настроить это, изменив политику перезапуска пода , но разумный вариант по умолчанию всегда перезапускать поды с экспоненциальной задержкой (ожидание 10 секунд, затем 20, затем 40 и т. д.) имеет большой смысл.
Это действительно мощная основная идея Kubernetes: вы просто объявляете, в каком состоянии должен находиться кластер, и Kubernetes это сделает. Таким образом, вы тратите больше времени на проектирование системы и меньше времени на ручное выполнение команд или нажатие кнопок, чтобы воплотить свой дизайн в жизнь.
Проблема: у моего контейнера никогда не должно быть простоев, даже если он выйдет из строя.
Kubernetes перезапускает серверную часть Project Kangaroo при сбое, но эти перезапуски по-прежнему приводят к простою в течение нескольких секунд, и даже несколько секунд — это плохо. Тем более, что однажды у вас возникла петля сбоя из-за действительно странного пограничного случая, и ваш сервис был недоступен на несколько минут. Вы действительно хотели бы, чтобы серверная часть была доступна даже во время сбоев и перезапусков.
Проще всего это сделать с помощью реплик . Вы просто запускаете один и тот же контейнер несколько раз одновременно, т. е. запускаете три реплики, и таким образом, если реплика 1 дает сбой, реплики 2 и 3 все еще могут обслуживать трафик. Да, и система должна автоматически запустить новый контейнер, чтобы довести количество реплик до 3. Таким образом, в следующий раз, когда произойдет сбой, у вас будет полный массив реплик, готовый справиться с ним.
В Kubernetes для этого используется Deployment .
# Standard Kubernetes fields for all resources: apiVersion, kind, metadata, spec
apiVersion: apps/v1
kind: Deployment
metadata:
name: kangaroo-backend-deployment
labels:
app: kangaroo-backend
# The `spec` is where the Deployment-specific stuff is defined
spec:
replicas: 3
# The `selector` defines which pods will get managed by this deployment.
# We tell Kubernetes to replicate the pod matching the label `app: kangaroo`
selector:
matchLabels:
app: kangaroo
role: backend
# The `template` defines a pod which will get managed by this deployment.
template:
metadata:
# Make sure the pod's labels match the labels the deployment is selecting (see above)
labels:
app: kangaroo
role: backend
# The Pod has its own spec, inside the spec of the Deployment.
# This spec defines what containers the Pod should run.
spec:
containers:
- name: kangaroo-backend
image: kangaroo-backend:1.14.2
ports:
- containerPort: 80
Развертывание управляет набором модулей. Это конкретное развертывание управляет любыми модулями с меткой app: kangaroo, и оно управляет ими, гарантируя, что всегда есть 3 реплики этого модуля. Мы также можем вложить определение самого пода в это развертывание.
Если вы примените этот манифест Kubernetes, вы увидите, что он создает развертывание. Однако это не создает явно соответствующие модули, поэтому на короткое время ни одна из реплик не работает. Но помните, Kubernetes является декларативным, а не императивным . Итак, Kubernetes замечает, что его кластер не соответствует заявленному вами предполагаемому состоянию (3 реплики). Так что потребуются некоторые действия, чтобы исправить это, например, запуск нового модуля реплики. Как только это действие будет завершено и ваш модуль появится, Kubernetes повторно оценит состояние кластера, заметит, что в нем по-прежнему меньше модулей, чем предполагалось, и создаст новую реплику. Это повторяется до тех пор, пока заданное вами развертывание не произойдет.
Проблема: мой контейнер не справляется с объемом получаемого трафика.
Project Kangaroo становится все более популярным, и ваш бэкенд получает слишком много трафика. Вы знаете решение – реплики. Реплики могут сделать службу более производительной и отказоустойчивой! К счастью, вы уже знаете, как использовать развертывания Kubernetes для репликации вашего контейнера. Таким образом, вы просто настраиваете спецификацию развертывания, увеличивая количество реплик. Теперь ваш сервис может масштабироваться в зависимости от объема трафика.
(Есть даже эластичное масштабирование, где вы можете программно определить какое-то свойство, например, «количество запросов на реплику в секунду должно быть меньше 1000», и позволить Kubernetes автоматически выбирать необходимое количество реплик. Это называется горизонтальным автоматическим масштабированием, и я не собираюсь чтобы покрыть это здесь, но вы можете прочитать больше )
Проблема: мне нужно развернуть новую версию моего бэкенда, не вызывая простоя
Каждую неделю вы выпускаете новую версию бэкенда Kangaroo. В первый раз, когда вы сделали это, вы просто удалили развертывание и создали новое развертывание с более новой версией контейнера kangaroo-backend. Это сработало, но вызвало несколько минут простоя, которого вы действительно пытаетесь избежать. Как вы можете обновить кенгуру версии 15 до версии 16, не вызывая простоев?
Это очень распространенная проблема, поэтому Kubernetes Deployments уже поддерживает ее. Это называется обновлением развертывания , и это легко. Просто отредактируйте развертывание и перейдите kangaroo-backend:1.15на kangaroo-backend:1.16(либо с помощью kubectl editинтерфейса командной строки, либо путем редактирования манифеста YAML, изменения образа контейнера и повторного запуска kubectl apply). Декларативное управление Kubernetes срабатывает и замечает, что развертывание, которое у вас есть в настоящее время (в контейнере kangaroo-backend:1.15), не совпадает с тем, что вы хотите ( kangaroo-backend:1.16). Таким образом, он будет выполнять пошаговое обновление : по одному, он будет
- Обратите внимание, что фактическое состояние кластера не соответствует заявленной спецификации (недостаточно реплик в версии 1.16).
- Запустите новый модуль в версии 1.16.
- Если этот модуль запустится успешно, Kubernetes заменит его на старый модуль в развертывании.
- Обратите внимание, что есть модуль (kangaroo-backend:1.15), который не является частью какой-либо заявленной спецификации, поэтому приведите систему в соответствие с объявленной спецификацией, остановив модуль.
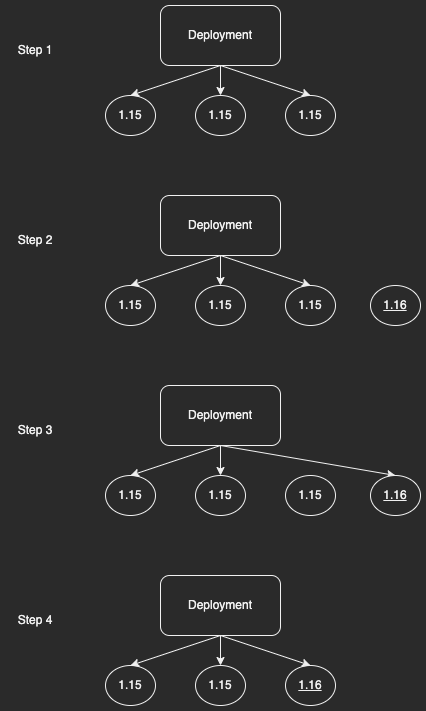
Это повторяется до тех пор, пока все устаревшие модули не исчезнут и останутся только современные модули.
Проблема: мне нужно направить трафик на все модули в развертывании.
Каждый модуль получает свой собственный IP-адрес кластера (IP-адрес, который имеет значение только в этом кластере Kubernetes — другие кластеры или более широкий Интернет ничего не знают об этих IP-адресах). Таким образом, вы можете отправлять трафик с интерфейса кенгуру на сервер кенгуру, используя этот IP-адрес.
Это работает нормально, пока ваш модуль не перезапустится или у вас не будет развертывания с несколькими модулями, потому что каждый из них будет иметь разные IP-адреса. Как ваши внешние интерфейсы узнают, на какие IP-адреса они должны отправлять кенгуру-бэкенд-трафик? Пришло время для нового вида Kubernetes под названием Сервис.
# The kangaroo-backend Service.
# Other services inside the Kubernetes cluster will address the
# kangaroo-backend containers using this service.
apiVersion: v1
kind: Service
metadata:
name: kangaroo-backend
labels:
app: kangaroo-backend
spec:
ports:
# Port 8080 of the Service will be forwarded to port 80 of one of the Pods.
- port: 8080
protocol: TCP
targetPort: 80
# Select which pods the service will proxy to
selector:
app: kangaroo
role: backend
Развертывание этой службы создает запись DNS в вашем кластере Kubernetes, например my-svc.my-namespace.svc.cluster-domain.example, или kangaroo-backend.kangaroo-team.svc.mycompany.com. Объект службы будет отслеживать, какие модули соответствуют его селекторам. Всякий раз, когда служба получает TCP-пакет на свой port, она перенаправляет его targetPortна соответствующий модуль.
Итак, теперь внешний интерфейс кенгуру будет просто отправлять свои запросы API на это внутреннее имя хоста kangaroo-backend.kangaroo-team.svc.mycompany.comкластера, а преобразователь DNS кластера сопоставит его со службой кенгуру, которая перенаправит его на какой-либо доступный под. Если у вас есть развертывание, оно гарантирует, что у вас достаточно подов для обработки трафика. Хороший!
Примечание. И службы, и развертывания выбирают модули с определенным набором меток, но у них разные обязанности. Сервисы обеспечивают балансировку трафика и обнаружение, а развертывание гарантирует, что ваши модули существуют в правильном количестве и правильной конфигурации. Обычно бэкенды/серверы, которые я развертываю в K8s, имеют 1 службу и 1 развертывание, выбирая одинаковые метки.
Проблема: балансировка нагрузки между подами
Мы только что рассмотрели, как сервис k8s позволяет вам обращаться к набору подов, даже когда поды входят в этот набор или покидают его (например, путем перезапуска или обновления). Если вы подумали «это похоже на балансировку нагрузки», то поздравляю, вы были правы!
Если вы используете службу k8s для маршрутизации трафика к вашему приложению, вы получаете базовую балансировку нагрузки 3 бесплатно. Если модуль выходит из строя, служба прекращает маршрутизацию трафика к нему и начинает маршрутизировать трафик к другим модулям с соответствующими метками (возможно, модулям в том же развертывании). Пока другие модули в кластере используют DNS-имя хоста службы, их запросы будут направляться на доступный модуль.
Проблема: я хочу принимать трафик из-за пределов кластера
До сих пор ваша служба принимала трафик от интерфейсов внутри кластера, используя имя хоста службы. Но эти кластерные IP-адреса и записи DNS имеют смысл только в кластере. Это означает, что другие сервисы в вашей компании могут нормально маршрутизироваться к серверной части Kangaroo. Но как вы можете принимать трафик из – за пределов кластера, например, интернет-трафик от ваших клиентов?
Вы развертываете два типа ресурсов: Ingress и IngressController .
- Ingress определяет правила для сопоставления внешнего трафика HTTP/S кластера с внутренними службами кластера. Оттуда ваша служба перенаправит его в модуль, как обсуждалось выше.
- IngressController выполняет эти правила. Ваша компания, вероятно, уже настроила Ingress Controller для вашего кластера. Проект Kubernetes поддерживает и поддерживает три конкретных IngressController (AWS, GCE и Nginx), но есть и другие популярные, такие как Contour , которые я использую.
Настройка IngressController, вероятно, является работой специализированной команды платформы, которая поддерживает ваш кластер k8s, или облачной платформой, которую вы используете. Поэтому мы не будем их освещать. Вместо этого мы просто поговорим о самом Ingress, который определяет правила сопоставления внешнего трафика с вашими сервисами.
Примечание. Удобно, что вы можете определять правила Ingress, которые абстрактно работают с любым конкретным IngressController, поэтому различные проекты могут предлагать конкурирующие контроллеры, совместимые с одним и тем же API Kubernetes.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: minimal-ingress
spec:
ingressClassName: kangaroo
rules:
- http:
paths:
- path: /api
pathType: Prefix
backend:
service:
name: kangaroo-backend
port:
number: 8080
Это создает Ingress, используя контроллер входящего трафика по умолчанию для нашего кластера. У Ingress есть одно правило, которое сопоставляет трафик, путь которого начинается с /api, с нашим кенгуру-бэкендом. Мы могли бы определить больше правил, если хотим, например, сопоставить /admin с какой-либо службой администрирования. Трафик, который не соответствует каким-либо правилам, обрабатывается по умолчанию вашим IngressController.
Проблема: я хочу ограничить сеть внутри кластера
Вы очень серьезно относитесь к безопасности в Project Kangaroo. Вы хотите проявлять инициативу в отношении безопасности, поэтому думаете: что, если кто-то взломает серверную часть кенгуру с помощью SQL-инъекции или чего-то еще. Вы хотите сдержать ущерб и убедиться, что злоумышленники не могут переключить свой контроль над серверной частью Kangaroo на контроль над другими службами.
Одним из простых способов смягчения последствий является использование сетевой политики Kubernetes для ограничения сетевых разрешений вашего проекта. Вы используете сетевые политики для ограничения:
- Ingress (от кого ваш сервис может получать трафик)
- Выход (кому ваш сервис может отправлять трафик)
Лучшей практикой безопасности является запрет по умолчанию всех сетей в вашем пространстве имен , а затем открытие определенных исключений для сетей, которые, как вы знаете, нужны вашей службе. Вот пример включения сети для кенгуру. Обратите внимание, что существуют отдельные правила для входа и выхода. Каждое правило входа состоит из двух частей:
fromговорит, какие виды услуг могут отправлять трафикportsговорит, на какие порты они могут отправлять трафик
В правилах исходящего трафика есть toи ports, определяющие, в какие пункты назначения ваша служба может отправлять трафик и какие порты в этих пунктах назначения разрешены.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: kangaroo-network-policy
labels:
app: kangaroo
role: network-policy
spec:
podSelector:
matchLabels:
app: kangaroo
role: backend
policyTypes:
- Ingress
- Egress
# Each element of `ingress` opens some port of Kangaroo to receive requests from a client.
ingress:
# Anything can ingress to the public API port
- ports:
- protocol: TCP
port: 80
# Hypothetical example: say your Platform team has configured cluster-wide metrics,
# you'll need to grant it access to your pod's metrics server. Your company will
# have examples for this. Assume kangaroo-backend serves metrics on TCP :81
- from:
- namespaceSelector:
matchLabels:
project: monitoring-system
ports:
- protocol: TCP
port: 81
# Each element of `egress` opens some port of Kangaroo to send requests to some server
egress:
# Say the Kangaroo backend calls into a membership microservice.
# You'll need to allow egress to it!
- ports:
- port: 443
to:
- namespaceSelector:
matchLabels:
project: membership
role: api
Проблема: я хочу использовать HTTP/S вне кластера и HTTP внутри кластера
Управление сертификатами TLS может быть головной болью — создание, управление, развертывание и повторное создание этих сертификатов довольно утомительно, и если что-то пойдет не так, вы можете случайно отключить весь трафик к своей службе. Поэтому, если вы уже правильно настроили свои сетевые политики (см. выше), вы решите не использовать TLS в конкретном кластере или пространстве имен. Поговорите со своей командой и посмотрите, имеет ли это смысл для вас.
Если это так, вы, вероятно, все еще хотите разрешить HTTP/S для внешнего трафика — в конце концов, в Интернете нет пространств имен или сетевых политик Kubernetes. Таким образом, вы должны настроить свой Ingress для завершения HTTP/S до того, как он отправит запросы в вашу службу. Это означает, что внешние клиенты будут выполнять рукопожатие TLS с вашим Ingress, а затем ваш Ingress перенаправит открытый текст HTTP в вашу службу.
Проблема: я хочу получить метрики о моем сервисе
Вы, вероятно, захотите собрать метрики о задержке вашего сервиса, количестве ответов HTTP класса 200/400/500 и т. д. Вы можете самостоятельно оснастить свой сервер чем-то вроде Prometheus, OpenMetrics или Honeycomb. Это работает нормально, но вы столкнетесь с двумя проблемами:
- Когда ваш сервис выходит из строя, вы не можете получить от него метрики
- Вы будете писать одни и те же метрики для каждой службы, которую когда-либо развертываете. Это становится повторяющимся и шаблонным.
Вместо этого большинство IngressController будут собирать кучу метрик. Например, Contour будет отслеживать каждый HTTP-запрос, который он перенаправляет в вашу службу, и отслеживать задержку и статус HTTP. Затем он предоставляет их в метриках Prometheus , которые вы можете очистить и отобразить в виде графика. Это действительно удобно, потому что вы экономите время, не внедряя эти метрики самостоятельно. И когда ваша служба выйдет из строя, вы узнаете об этом, потому что увидите показатели Contour для этого пространства имен/службы, показывающие всплески задержки или ответы HTTP 5xx.
Проблема: мне нужна изоляция от других проектов, использующих тот же кластер
Ваш проект k8s прошел успешно. Вы отправили проект, всем он нравится. Подходит технический директор и спрашивает: «Как Kubernetes?» Сморгнув слезы, ты говоришь: «Не так уж и плохо». Ваша команда покупает вам кружку с надписью «Лучший писатель YAML».
Другие команды учатся на вашем успехе и начинают развертывать свои проекты в Kubernetes. Однажды они приходят к вам и жалуются, что ваше Развертывание нарушило их Развертывание. Хм? Что случилось?
Получается, вы написали Deployment, который сопоставляет любые pod’ы с метками role: backend. Это прекрасно работает, когда вы единственная команда, работающая в k8s — вы пишете шаблон модуля с меткой role: backend, и он реплицируется в файле Deployment. Что, если другая команда развернет собственный модуль с помощью role: backend? Ваше развертывание будет соответствовать этому поду и начнет воспроизводить материалы другой команды! Что вы должны сделать?
Одним из решений было бы всегда добавлять небольшой префикс к этим меткам, поэтому вместо того, чтобы backendваши команды соглашались использовать такие метки, как kangaroo-backendи emu-backend. Это зависит от того, насколько дисциплинирован каждый, чтобы соблюдать правила. Даже если все согласны, рано или поздно кто-то может ошибиться, оступиться и развернуть что-то с неправильным ярлыком. Это может привести к серьезным проблемам! Представьте, если бы вы случайно воспроизвели сервис, который должен был быть синглтоном!
К счастью, в Kubernetes есть встроенный способ изолировать команды друг от друга. Это называется пространством имен . Они позволяют изолировать команды или проекты друг от друга, чтобы их имена не конфликтовали. Точно так же, как несколько типов могут экспортировать методы с одним и тем же именем, например, String::newи File::new. Просто используйте --namespaceв CLI kubectl, чтобы выбрать, какое пространство имен вы хотите развернуть.
Примечание. В Cloudflare мы обычно используем два пространства имен для каждой команды, например, «предотвращение потери данных — подготовка» и «предотвращение потери данных — производство». Затем, когда мы развертываем новые изменения K8s, мы можем развернуть их на этапе подготовки, чтобы убедиться, что они работают, а затем развернуть их в рабочей среде, зная, что наши изменения не будут мешать другим командам.
Вывод
Веб-приложения сталкиваются с одними и теми же проблемами, независимо от того, где они развернуты. Управление и балансировка нагрузки между репликами, ограничение сетевых привилегий, обновления с нулевым временем простоя — все это не является уникальным для Kubernetes. Возможно, вы уже знаете, как решить их в своей любимой модели развертывания. Kubernetes также предоставляет довольно хорошие готовые решения для их решения, вам просто нужно перевести стандартные решения на жаргон Kubernetes (модули, развертывания и т. д.).
Резюме:
- Под — это минимальная единица развертывания. Модуль запускает один (или несколько) контейнеров.
- Реплицируйте свои модули с помощью Deployments . Это дает вам:
- Устойчивость к сбоям
- Последовательные обновления с нулевым временем простоя
- Масштабирование для увеличения трафика
- Балансировка нагрузки между модулями в вашем развертывании с помощью [Service].
- Ограничьте сетевой доступ вашего модуля с помощью сетевой политики , чтобы уменьшить уязвимую поверхность .
- Сопоставьте внешний трафик с вашим модулем с помощью Ingress .
- Правила входа сопоставляют определенный тип трафика (протокол, URL-адрес и т. д.) с определенной службой.
- Правила выполняются IngressController . Администраторы вашего кластера, вероятно, уже настроили его.
- Изолируйте команды и проекты друг от друга с помощью пространств имен .
Большое спасибо Sana Oshika , Jesse Li , Mingwei Zhang и Rina Sadun за действительно полезные отзывы о черновиках этого поста. И отдельное спасибо Тиму и Терину из Cloudflare, которые очень помогли мне научиться понимать и использовать Kubernetes. Они всегда отвечают на вопросы и улучшают опыт разработчиков. Они действительно иллюстрируют, как выглядит отличная команда платформы.
Статья является переводом blog.adamchalmers.com