Contents
- 1 Что такое Керас?
- 1.1 Что такое Бэкенд?
- 1.2 Серверная часть Theano, Tensorflow и CNTK
- 1.3 Сравнение серверных частей
- 1.4 Керас против Tensorflow
- 1.5 Преимущества Кераса
- 1.6 Недостатки Кераса
- 1.7 Установка Кераса
- 1.8 Прямая установка или виртуальная среда
- 1.9 Установка Keras на Amazon Web Service (AWS)
- 1.10 Как установить Keras на Amazon SageMaker
- 1.11 Установите Керас в Linux
- 1.12 Как установить Керас в Windows
- 1.13 Основы Keras для глубокого обучения
- 1.14 Тонкая настройка предварительно обученных моделей в Keras и способы их использования
- 1.15 Загрузка наших данных в корзину AWS S3
- 1.16 Подготовка данных
- 1.17 Создание нашей модели из VGG16
- 1.18 Тестирование нашей модели
- 1.19 Нейронная сеть распознавания лиц с Keras
- 1.20 Какой из них лучше? Керас или Tensorflow
- 1.21 Резюме
Что такое Керас?
Keras — это библиотека нейронной сети с открытым исходным кодом, написанная на Python, которая работает поверх Theano или Tensorflow. Он разработан, чтобы быть модульным, быстрым и простым в использовании. Он был разработан Франсуа Шолле, инженером Google. Keras не поддерживает низкоуровневые вычисления. Вместо этого для этого используется другая библиотека, называемая «Backend.
Keras — это высокоуровневая оболочка API для низкоуровневого API, способная работать поверх TensorFlow, CNTK или Theano. Keras High-Level API управляет тем, как мы создаем модели, определяем слои или настраиваем несколько моделей ввода-вывода. На этом уровне Keras также компилирует нашу модель с функциями потерь и оптимизатора, процесс обучения с функцией подгонки. Keras в Python не обрабатывает низкоуровневый API, такой как создание вычислительного графа, создание тензоров или других переменных, потому что это обрабатывается «бэкэнд-движком».
Что такое Бэкенд?
Backend — это термин в Keras, который выполняет все низкоуровневые вычисления, такие как тензорные произведения, свертки и многое другое, с помощью других библиотек, таких как Tensorflow или Theano. Таким образом, «бэкенд-движок» будет выполнять вычисления и разработку моделей. Tensorflow — это «бэкэнд-движок» по умолчанию, но мы можем изменить его в конфигурации.
Серверная часть Theano, Tensorflow и CNTK

Theano — это проект с открытым исходным кодом, разработанный группой MILA в Университете Монреаля, Квебек, Канада. Это был первый широко используемый фреймворк. Это библиотека Python, которая помогает в многомерных массивах для математических операций с использованием Numpy или Scipy. Theano может использовать графические процессоры для более быстрых вычислений, а также автоматически строить символические графики для вычисления градиентов. На своем веб-сайте Theano утверждает, что может распознавать численно нестабильные выражения и вычислять их с помощью более стабильных алгоритмов, что очень полезно для наших нестабильных выражений.
С другой стороны, Tensorflow — восходящая звезда в сфере глубокого обучения. Разработанный командой Google Brain, это самый популярный инструмент глубокого обучения. Обладая множеством функций, исследователи вносят свой вклад в разработку этой структуры для целей глубокого обучения.

Другой серверный движок для Keras — Microsoft Cognitive Toolkit или CNTK. Это среда глубокого обучения с открытым исходным кодом, разработанная командой Microsoft. Он может работать на нескольких графических процессорах или на нескольких машинах для обучения модели глубокого обучения в больших масштабах. В некоторых случаях о CNTK сообщалось быстрее, чем о других фреймворках, таких как Tensorflow или Theano. Далее в этом руководстве по Keras CNN мы сравним серверные части Theano, TensorFlow и CNTK.
Сравнение серверных частей
Нам нужно сделать тест, чтобы узнать сравнение между этими двумя бэкэндами. Как видно из бенчмарка Jeong-Yoon Lee, сравнивается производительность 3 разных бэкендов на разном оборудовании. И в результате Theano медленнее, чем другой бэкэнд, сообщается, что он в 50 раз медленнее, но точность близка друг к другу.
Еще один бенчмарк-тест провел Jasmeet Bhatia . Он сообщил, что Theano медленнее, чем Tensorflow для некоторых тестов. Но общая точность почти одинакова для каждой тестируемой сети.
Итак, между Theano, Tensorflow и CTK очевидно, что TensorFlow лучше, чем Theano. С TensorFlow время вычислений намного короче, а CNN лучше, чем другие.
Далее в этом руководстве по Keras Python мы узнаем о разнице между Keras и TensorFlow ( Keras vs Tensorflow ).
Керас против Tensorflow
| Параметры | Керас | Тензорный поток |
|---|---|---|
| Тип | Высокоуровневая оболочка API | Низкоуровневый API |
| Сложность | Простота в использовании, если вы язык Python | Вам нужно изучить синтаксис использования некоторых функций Tensorflow. |
| Цель | Быстрое развертывание для создания модели со стандартными слоями | Позволяет создавать произвольный вычислительный график или слои модели |
| Инструменты | Использует другой инструмент отладки API, например TFDBG. | Вы можете использовать инструменты визуализации Tensorboard |
| Сообщество | Большие активные сообщества | Большие активные сообщества и широко используемые ресурсы |
Преимущества Кераса
Быстрое развертывание и простота понимания
Keras очень быстро создает сетевую модель. Если вы хотите создать простую сетевую модель из нескольких строк, Python Keras может вам в этом помочь. Посмотрите на пример Keras ниже:
from keras.models import Sequential from keras.layers import Dense, Activation model = Sequential() model.add(Dense(64, activation='relu', input_dim=50)) #input shape of 50 model.add(Dense(28, activation='relu')) #input shape of 50 model.add(Dense(10, activation='softmax'))
Благодаря дружественному API мы можем легко понять процесс. Написание кода с помощью простой функции и отсутствие необходимости устанавливать несколько параметров.
Поддержка большого сообщества
Есть много сообществ ИИ, которые используют Keras для своей платформы глубокого обучения. Многие из них публикуют свои коды, а также учебные пособия для широкой публики.
Иметь несколько бэкэндов
Вы можете выбрать Tensorflow, CNTK и Theano в качестве серверной части с Keras. Вы можете выбрать другой бэкэнд для разных проектов в зависимости от ваших потребностей. Каждый бэкэнд имеет свое уникальное преимущество.
Кроссплатформенность и простое развертывание модели
Благодаря множеству поддерживаемых устройств и платформ вы можете развернуть Keras на любом устройстве, например
- iOS с CoreML
- Android с Tensorflow Android,
- Веб-браузер с поддержкой .js
- Облачный движок
- Raspberry Pi
Поддержка нескольких графических процессоров
Вы можете обучать Keras на одном графическом процессоре или использовать несколько графических процессоров одновременно. Потому что Keras имеет встроенную поддержку параллелизма данных, поэтому он может обрабатывать большие объемы данных и ускорять время, необходимое для их обучения.
Недостатки Кераса
Не может обрабатывать низкоуровневый API
Keras обрабатывает только высокоуровневый API, который работает поверх других фреймворков или серверных движков, таких как Tensorflow, Theano или CNTK. Так что это не очень полезно, если вы хотите создать свой собственный абстрактный слой для своих исследовательских целей, потому что в Keras уже есть предварительно настроенные слои.
Установка Кераса
В этом разделе мы рассмотрим различные способы установки Keras.
Прямая установка или виртуальная среда
Какой из них лучше? Прямая установка на текущий Python или использование виртуальной среды? Я предлагаю использовать виртуальную среду, если у вас много проектов. Хотите знать, почему? Это связано с тем, что разные проекты могут использовать разные версии библиотеки keras.
Например, у меня есть проект, для которого требуется Python 3.5 с использованием OpenCV 3.3 с более старым бэкэндом Keras-Theano, но в другом проекте мне нужно использовать Keras с последней версией и Tensorflow, поскольку он поддерживает Python 3.6.6.
Мы же не хотим, чтобы библиотеки Keras конфликтовали друг с другом, верно? Поэтому мы используем виртуальную среду для локализации проекта с помощью библиотеки определенного типа или можем использовать другую платформу, такую как облачный сервис, для выполнения наших вычислений за нас, например Amazon Web Service.
Установка Keras на Amazon Web Service (AWS)
Amazon Web Service — это платформа, которая предлагает услуги и продукты облачных вычислений для исследователей или любых других целей. AWS арендует свое оборудование, сеть, базу данных и т. д., чтобы мы могли использовать их напрямую из Интернета. Одним из популярных сервисов AWS для целей глубокого обучения является Amazon Machine Image Deep Learning Service или DL.
Подробные инструкции по использованию AWS см. в этом руководстве.
Примечание об AMI: вам будут доступны следующие AMI
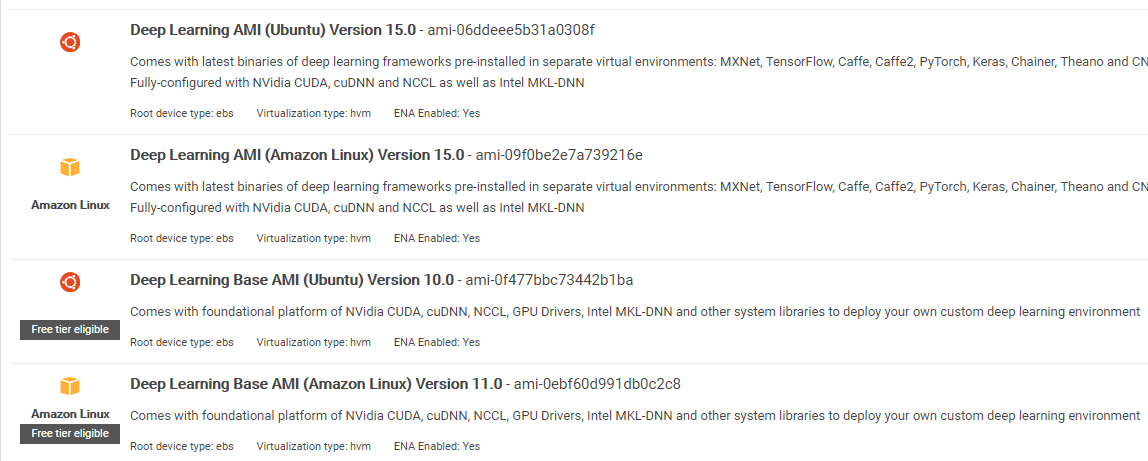
AWS Deep Learning AMI — это виртуальная среда в сервисе AWS EC2, которая помогает исследователям и практикам работать с Deep Learning. DLAMI предлагает от небольших процессоров до мощных многопроцессорных ядер с предварительно настроенными CUDA, cuDNN и поставляется с различными платформами глубокого обучения.
Если вы хотите использовать его мгновенно, вам следует выбрать Deep Learning AMI, поскольку он поставляется с предустановленными популярными платформами глубокого обучения.
Но если вы хотите попробовать собственную среду глубокого обучения для исследований, вам следует установить AMI Deep Learning Base, поскольку он поставляется с основными библиотеками, такими как CUDA, cuDNN, драйверами графических процессоров и другими необходимыми библиотеками для работы в вашей среде глубокого обучения.
Как установить Keras на Amazon SageMaker
Amazon SageMaker — это платформа глубокого обучения, которая поможет вам в обучении и развертывании сети глубокого обучения с лучшим алгоритмом.
Для новичка это, безусловно, самый простой способ использования Keras. Ниже описан процесс установки Keras на Amazon SageMaker:
Шаг 1) Откройте Amazon SageMaker
На первом этапе откройте консоль Amazon Sagemaker и нажмите «Создать экземпляр ноутбука».

Шаг 2) Введите данные
- Введите имя вашей записной книжки.
- Создайте роль IAM. Будет создана роль AMI Роль Amazon IAM в формате AmazonSageMaker-Executionrole-ГГГГММДД|ЧЧммСС.
- Наконец, выберите «Создать экземпляр записной книжки». Через несколько секунд Amazon Sagemaker запускает экземпляр ноутбука.

Примечание . Если вы хотите получить доступ к ресурсам из своего VPC, включите прямой доступ в Интернет. В противном случае у этого экземпляра ноутбука не будет доступа в Интернет, поэтому невозможно будет обучать или размещать модели.
Шаг 3) Запустите экземпляр
Нажмите «Открыть», чтобы запустить экземпляр.

Шаг 4) Начать кодирование
В Jupyter нажмите «Создать»> conda_tensorflow_p36, и вы готовы кодировать.

Установите Керас в Linux
Чтобы включить Keras с Tensorflow в качестве внутреннего механизма, нам нужно сначала установить Tensorflow. Запустите эту команду, чтобы установить тензорный поток с процессором (без графического процессора)
pip install --upgrade tensorflow если вы хотите включить поддержку графического процессора для тензорного потока, вы можете использовать эту команду
pip install --upgrade tensorflow-gpu

давайте проверим в Python, чтобы убедиться, что наша установка прошла успешно, набрав
user@user:~$ python Python 3.6.4 (default, Mar 20 2018, 11:10:20) [GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import tensorflow >>>
если нет сообщения об ошибке, процесс установки прошел успешно
Установить Керас
После установки Tensorflow приступим к установке keras. Введите эту команду в терминал
pip install keras
он начнет установку Keras, а также всех его зависимостей. Вы должны увидеть что-то вроде этого:

Проверка
Прежде чем мы начнем использовать Keras, мы должны проверить, использует ли наш Keras Tensorflow в качестве серверной части, открыв файл конфигурации:
gedit ~/.keras/keras.json
вы должны увидеть что-то вроде этого
{
"floatx": "float32",
"epsilon": 1e-07,
"backend": "tensorflow",
"image_data_format": "channels_last"
}
как видите, «бэкэнд» использует tensorflow. Это означает, что keras использует Tensorflow в качестве серверной части, как мы и ожидали.
а теперь запустите его на терминале, набрав
user@user:~$ python3 Python 3.6.4 (default, Mar 20 2018, 11:10:20) [GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import keras Using TensorFlow backend. >>>
Как установить Керас в Windows
Прежде чем мы установим Tensorflow и Keras, мы должны установить Python, pip и virtualenv. Если вы уже установили эти библиотеки, вам следует перейти к следующему шагу, в противном случае сделайте следующее:
Установите Python 3, скачав по этой ссылке
Установите pip, запустив этот
Установите virtualenv с помощью этой команды
pip3 install –U pip virtualenv
Установите Microsoft Visual C++ 2015 Redistributable Update 3
- Перейдите на сайт загрузки Visual Studio https://www.microsoft.com/en-us/download/details.aspx?id=53587 .
- Выберите распространяемые компоненты и инструменты сборки
- Загрузите и установите распространяемый компонент Microsoft Visual C++ 2015 с обновлением 3.
Затем запустите этот скрипт
pip3 install virtualenv
Настройка виртуальной среды
Это используется для изоляции рабочей системы от основной системы.
virtualenv --system-site-packages --p python3 ./venv
Активировать среду
.\venv\Scripts\activate
После подготовки среды установка Tensorflow и Keras остается такой же, как в Linux. Далее в этом учебнике по глубокому обучению с помощью Keras мы узнаем об основах Keras для глубокого обучения.
Основы Keras для глубокого обучения
Основной структурой в Keras является модель, которая определяет полный граф сети. Вы можете добавить дополнительные слои к существующей модели, чтобы создать пользовательскую модель, необходимую для вашего проекта.
Вот как создать последовательную модель и несколько часто используемых слоев в глубоком обучении.
1. Последовательная модель
from keras.models import Sequential from keras.layers import Dense, Activation,Conv2D,MaxPooling2D,Flatten,Dropout model = Sequential()
2. Сверточный слой
Это пример сверточного слоя Keras Python в качестве входного слоя с входной формой 320x320x3, с 48 фильтрами размером 3×3 и использованием ReLU в качестве функции активации.
input_shape=(320,320,3) #this is the input shape of an image 320x320x3 model.add(Conv2D(48, (3, 3), activation='relu', input_shape= input_shape)) другой тип
model.add(Conv2D(48, (3, 3), activation='relu'))
3. Слой MaxPooling
Чтобы уменьшить входное представление, используйте MaxPool2d и укажите размер ядра.
model.add(MaxPooling2D(pool_size=(2, 2)))
4. Плотный слой
добавление полносвязного слоя с указанием выходного размера
model.add(Dense(256, activation='relu'))
5. Выпадающий слой
Добавление слоя отсева с вероятностью 50%
model.add(Dropout(0.5))
Компиляция, обучение и оценка
После того, как мы определим нашу модель, давайте начнем их обучать. Сначала необходимо скомпилировать сеть с функцией потерь и функцией оптимизатора. Это позволит сети менять веса и минимизировать потери.
odel.compile(loss='mean_squared_error', optimizer='adam')
Теперь, чтобы начать обучение, используйте fit для подачи данных обучения и проверки в модель. Это позволит вам обучать сеть партиями и устанавливать эпохи.
model.fit (X_train, X_train, batch_size = 32, эпохи = 10, validation_data = (x_val, y_val))
Наш последний шаг — оценить модель с помощью тестовых данных.
score = model.evaluate(x_test, y_test, batch_size=32)
Давайте попробуем использовать простую линейную регрессию
import keras
from keras.models import Sequential
from keras.layers import Dense, Activation
import numpy as np
import matplotlib.pyplot as plt
x = data = np.linspace(1,2,200)
y = x*4 + np.random.randn(*x.shape) * 0.3
model = Sequential()
model.add(Dense(1, input_dim=1, activation='linear'))
model.compile(optimizer='sgd', loss='mse', metrics=['mse'])
weights = model.layers[0].get_weights()
w_init = weights[0][0][0]
b_init = weights[1][0]
print('Linear regression model is initialized with weights w: %.2f, b: %.2f' % (w_init, b_init))
model.fit(x,y, batch_size=1, epochs=30, shuffle=False)
weights = model.layers[0].get_weights()
w_final = weights[0][0][0]
b_final = weights[1][0]
print('Linear regression model is trained to have weight w: %.2f, b: %.2f' % (w_final, b_final))
predict = model.predict(data)
plt.plot(data, predict, 'b', data , y, 'k.')
plt.show()
После обучения данных вывод должен выглядеть так
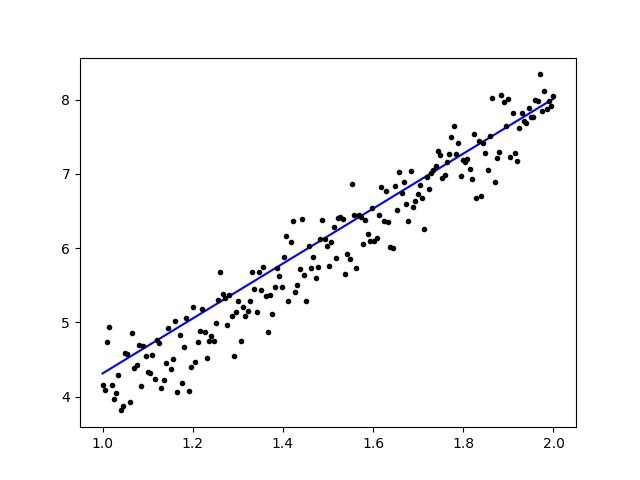
с начальным весом
Linear regression model is initialized with weights w: 0.37, b: 0.00
и конечный вес
Linear regression model is trained to have weight w: 3.70, b: 0.61
Тонкая настройка предварительно обученных моделей в Keras и способы их использования
Почему мы используем модели Fine Tune и когда мы их используем
Тонкая настройка — это задача по настройке предварительно обученной модели таким образом, чтобы параметры адаптировались к новой модели. Когда мы хотим обучить с нуля новую модель, нам нужен большой объем данных, чтобы сеть могла найти все параметры. Но в этом случае мы будем использовать предварительно обученную модель, поэтому параметры уже изучены и имеют вес.
Например, если мы хотим обучить нашу собственную модель Keras решению задачи классификации, но у нас есть только небольшой объем данных, мы можем решить эту проблему с помощью метода передачи обучения + тонкой настройки.
Используя предварительно обученную сеть и веса, нам не нужно обучать всю сеть. Нам просто нужно обучить последний слой, который используется для решения нашей задачи, так как мы называем его методом тонкой настройки.
Подготовка сетевой модели
Для предварительно обученной модели мы можем загрузить различные модели, которые уже есть в библиотеке Keras, например:
- ВГГ16
- НачалоV3
- Реснет
- Мобильная сеть
- Восприятие
- НачалоResNetV2
Но в этом процессе мы будем использовать сетевую модель VGG16 и imageNet в качестве нашего веса для модели. Мы настроим сеть для классификации 8 различных типов классов, используя изображения из набора данных Kaggle Natural Images.
Архитектура модели VGG16

Загрузка наших данных в корзину AWS S3
Для нашего учебного процесса мы будем использовать изображение естественных изображений из 8 различных классов, таких как самолеты, автомобиль, кошка, собака, цветок, фрукт, мотоцикл и человек. Во-первых, нам нужно загрузить наши данные в корзину Amazon S3.
Корзина Amazon S3
Шаг 1) После входа в свою учетную запись S3 давайте создадим корзину, запустив Create Bucket .

Шаг 2) Теперь выберите имя корзины и свой регион в соответствии с вашей учетной записью. Убедитесь, что имя корзины доступно. После этого нажмите Создать.
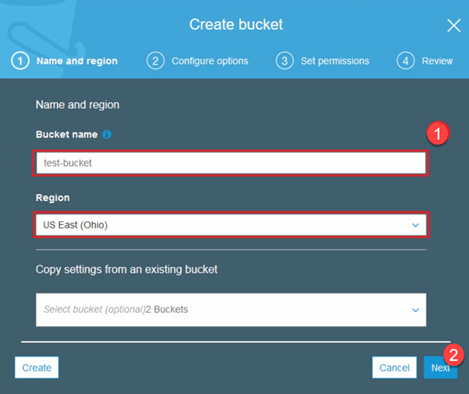
Шаг 3) Как видите, ваш Bucket готов к использованию. Но, как вы можете видеть, доступ не является общедоступным, это хорошо для вас, если вы хотите сохранить его приватным для себя. Вы можете изменить это ведро для общего доступа в свойствах ведра.

Шаг 4) Теперь вы начинаете загружать свои тренировочные данные в свой Bucket. Здесь я загружу файл tar.gz, состоящий из картинок для обучения и тестирования.

Шаг 5) Теперь нажмите на свой файл и скопируйте ссылку , чтобы мы могли его скачать.

Подготовка данных
Нам нужно сгенерировать наши обучающие данные с помощью Keras ImageDataGenerator.
Сначала вы должны скачать с помощью wget ссылку на ваш файл из S3 Bucket.
!wget https://s3.us-east-2.amazonaws.com/naturalimages02/images.tar.gz !tar -xzf images.tar.gz После загрузки данных приступим к процессу обучения.
rom keras.preprocessing.image import ImageDataGenerator
import numpy as np
import matplotlib.pyplot as plt
train_path = 'images/train/'
test_path = 'images/test/'
batch_size = 16
image_size = 224
num_class = 8
train_datagen = ImageDataGenerator(validation_split=0.3,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
train_generator = train_datagen.flow_from_directory(
directory=train_path,
target_size=(image_size,image_size),
batch_size=batch_size,
class_mode='categorical',
color_mode='rgb',
shuffle=True)
ImageDataGenerator создаст данные X_training из каталога. Подкаталог в этом каталоге будет использоваться как класс для каждого объекта. Изображение будет загружено в цветовом режиме RGB, в режиме категориального класса для данных Y_training с размером пакета 16. Наконец, перетасуйте данные.
Давайте посмотрим на наши изображения случайным образом, построив их с помощью matplotlib.
x_batch, y_batch = train_generator.next()
fig=plt.figure()
columns = 4
rows = 4
for i in range(1, columns*rows):
num = np.random.randint(batch_size)
image = x_batch[num].astype(np.int)
fig.add_subplot(rows, columns, i)
plt.imshow(image)
plt.show()

После этого давайте создадим нашу сетевую модель из VGG16 с предварительно обученным весом imageNet. Мы заморозим эти слои, чтобы слои нельзя было обучать, чтобы сократить время вычислений.
Создание нашей модели из VGG16
import keras
from keras.models import Model, load_model
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
from keras.applications.vgg16 import VGG16
#Load the VGG model
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(image_size, image_size, 3))
print(base_model.summary())
# Freeze the layers
for layer in base_model.layers:
layer.trainable = False
# # Create the model
model = keras.models.Sequential()
# # Add the vgg convolutional base model
model.add(base_model)
# # Add new layers
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dense(1024, activation='relu'))
model.add(Dense(num_class, activation='softmax'))
# # Show a summary of the model. Check the number of trainable parameters
print(model.summary())
Как вы можете видеть ниже, краткое изложение нашей сетевой модели. Из входных данных из слоев VGG16 мы добавляем 2 полносвязных слоя,
которые будут извлекать 1024 функции, и выходной слой, который будет вычислять 8 классов с активацией softmax.
Layer (type) Output form Parameter #
================================================= ===============
vgg16 (Model) (No, 7, 7, 512) 14714688
_________________________________________________________________
flatten_1 (Flatten) (No, 25088) 0
_________________________________________________________________
density_1 (Dense) (None, 1024) 25691136
_________________________________________________________________
density_2 (Dense) (None, 1024) 1049600
_________________________________________________________________
density_3 (Dense) (None, 8) 8200
================================================= ===============
Total parameters: 41 463 624
Trainable parameters: 26,748,936
Unlearnable parameters: 14,714,688
Подготовка
# # Compile the model
from keras.optimizers import SGD
model.compile(loss='categorical_crossentropy',
optimizer=SGD(lr=1e-3),
metrics=['accuracy'])
# # Start the training process
# model.fit(x_train, y_train, validation_split=0.30, batch_size=32, epochs=50, verbose=2)
# # #save the model
# model.save('catdog.h5')
history = model.fit_generator(
train_generator,
steps_per_epoch=train_generator.n/batch_size,
epochs=10)
model.save('fine_tune.h5')
# summarize history for accuracy
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.title('loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['loss'], loc='upper left')
plt.show()
Полученные результаты
Epoch 1/10 432/431 [==============================] - 53s 123ms/step - loss: 0.5524 - acc: 0.9474 Epoch 2/10 432/431 [==============================] - 52s 119ms/step - loss: 0.1571 - acc: 0.9831 Epoch 3/10 432/431 [==============================] - 51s 119ms/step - loss: 0.1087 - acc: 0.9871 Epoch 4/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0624 - acc: 0.9926 Epoch 5/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0591 - acc: 0.9938 Epoch 6/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0498 - acc: 0.9936 Epoch 7/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0403 - acc: 0.9958 Epoch 8/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0248 - acc: 0.9959 Epoch 9/10 432/431 [==============================] - 51s 119ms/step - loss: 0.0466 - acc: 0.9942 Epoch 10/10 432/431 [==============================] - 52s 120ms/step - loss: 0.0338 - acc: 0.9947

Как видите, наши потери значительно снижены, а точность почти 100%. Для тестирования нашей модели мы случайным образом выбрали изображения из Интернета и поместили их в тестовую папку с другим классом для тестирования.
Тестирование нашей модели
model = load_model('fine_tune.h5')
test_datagen = ImageDataGenerator()
train_generator = train_datagen.flow_from_directory(
directory=train_path,
target_size=(image_size,image_size),
batch_size=batch_size,
class_mode='categorical',
color_mode='rgb',
shuffle=True)
test_generator = test_datagen.flow_from_directory(
directory=test_path,
target_size=(image_size, image_size),
color_mode='rgb',
shuffle=False,
class_mode='categorical',
batch_size=1)
filenames = test_generator.filenames
nb_samples = len(filenames)
fig=plt.figure()
columns = 4
rows = 4
for i in range(1, columns*rows -1):
x_batch, y_batch = test_generator.next()
name = model.predict(x_batch)
name = np.argmax(name, axis=-1)
true_name = y_batch
true_name = np.argmax(true_name, axis=-1)
label_map = (test_generator.class_indices)
label_map = dict((v,k) for k,v in label_map.items()) #flip k,v
predictions = [label_map[k] for k in name]
true_value = [label_map[k] for k in true_name]
image = x_batch[0].astype(np.int)
fig.add_subplot(rows, columns, i)
plt.title(str(predictions[0]) + ':' + str(true_value[0]))
plt.imshow(image)
plt.show()
И наш тест приведен ниже! Только 1 изображение неверно предсказано из теста из 14 изображений!

Нейронная сеть распознавания лиц с Keras
Зачем нам нужно признание
Нам нужно Распознавание, чтобы нам было легче распознавать или идентифицировать лицо человека, тип объектов, предполагаемый возраст человека по его лицу или даже знать выражение лица этого человека.

Может быть, вы понимаете, что каждый раз, когда вы пытаетесь отметить лицо вашего друга на фотографии, функция Facebook делает это за вас, то есть отмечает лицо вашего друга без необходимости предварительно отмечать его. Это распознавание лиц, применяемое Facebook, чтобы нам было проще отмечать друзей.
Итак, как это работает? Каждый раз, когда мы отмечаем лицо нашего друга, искусственный интеллект Facebook запоминает его и пытается предсказать, пока не получит правильный результат. Та же система, которую мы будем использовать, чтобы сделать наше собственное распознавание лиц. Давайте начнем создавать собственное распознавание лиц с помощью глубокого обучения.
Сетевая модель
Мы будем использовать сетевую модель VGG16, но с весом VGGFace.
Архитектура модели VGG16

Что такое VGGFace? это реализация Keras технологии Deep Face Recognition, представленная Parkhi, Omkar M. et al. «Глубокое распознавание лиц». БМВК (2015). Фреймворк использует VGG16 в качестве сетевой архитектуры.
Вы можете скачать VGGFace с github
from keras.applications.vgg16 import VGG16
from keras_vggface.vggface import VGGFace
face_model = VGGFace(model='vgg16',
weights='vggface',
input_shape=(224,224,3))
face_model.summary()
Как вы можете видеть сводку по сети
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
conv1_1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
conv1_2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
pool1 (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
conv2_1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
conv2_2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
pool2 (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
conv3_1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
conv3_2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
conv3_3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
pool3 (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
conv4_1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
conv4_2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
conv4_3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
pool4 (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
conv5_1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
conv5_2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
conv5_3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
pool5 (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc6 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc6/relu (Activation) (None, 4096) 0
_________________________________________________________________
fc7 (Dense) (None, 4096) 16781312
_________________________________________________________________
fc7/relu (Activation) (None, 4096) 0
_________________________________________________________________
fc8 (Dense) (None, 2622) 10742334
_________________________________________________________________
fc8/softmax (Activation) (None, 2622) 0
=================================================================
Total params: 145,002,878
Trainable params: 145,002,878
Non-trainable params: 0
_________________________________________________________________
Traceback (most recent call last):
мы проведем Transfer Learning + Fine Tuning, чтобы ускорить обучение с небольшими наборами данных. Во-первых, мы заморозим базовые слои, чтобы слои не поддавались обучению.
for layer in face_model.layers:
layer.trainable = False
затем мы добавляем наш собственный слой для распознавания наших тестовых лиц. Мы добавим 2 полносвязных слоя и выходной слой с 5 людьми для обнаружения.
from keras.models import Model, Sequential
from keras.layers import Input, Convolution2D, ZeroPadding2D, MaxPooling2D, Flatten, Dense, Dropout, Activation
person_count = 5
last_layer = face_model.get_layer('pool5').output
x = Flatten(name='flatten')(last_layer)
x = Dense(1024, activation='relu', name='fc6')(x)
x = Dense(1024, activation='relu', name='fc7')(x)
out = Dense(person_count, activation='softmax', name='fc8')(x)
custom_face = Model(face_model.input, out)
Давайте посмотрим на нашу сводку по сети
Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ conv1_1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ conv1_2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ pool1 (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ conv2_1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ conv2_2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ pool2 (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ conv3_1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ conv3_2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ conv3_3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ pool3 (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ conv4_1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ conv4_2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ conv4_3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ pool4 (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ conv5_1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv5_2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ conv5_3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ pool5 (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc6 (Dense) (None, 1024) 25691136 _________________________________________________________________ fc7 (Dense) (None, 1024) 1049600 _________________________________________________________________ fc8 (Dense) (None, 5) 5125 ================================================================= Total params: 41,460,549 Trainable params: 26,745,861 Non-trainable params: 14,714,688
Как вы можете видеть выше, после слоя pool5 он будет сведен в единый вектор признаков, который будет использоваться плотным слоем для окончательного распознавания.
Подготовка наших лиц
Теперь давайте подготовим наши лица. Я сделал каталог, состоящий из 5 известных людей
- Джек Ма
- Джейсон Стэтхэм
- Джонни Депп
- Роберт Дауни-младший
- Роуэн Аткинсон
Каждая папка содержит 10 изображений для каждого процесса обучения и оценки. Это очень небольшой объем данных, но это проблема, верно?
Мы воспользуемся помощью инструмента Keras для подготовки данных. Эта функция будет повторяться в папке набора данных, а затем подготавливать ее для использования в обучении.
from keras.preprocessing.image import ImageDataGenerator
batch_size = 5
train_path = 'data/'
eval_path = 'eval/'
train_datagen = ImageDataGenerator(rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
valid_datagen = ImageDataGenerator(rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
train_generator = train_datagen.flow_from_directory(
train_path,
target_size=(image_size,image_size),
batch_size=batch_size,
class_mode='sparse',
color_mode='rgb')
valid_generator = valid_datagen.flow_from_directory(
directory=eval_path,
target_size=(224, 224),
color_mode='rgb',
batch_size=batch_size,
class_mode='sparse',
shuffle=True,
)
Обучение нашей модели
Давайте начнем наш процесс обучения с компиляции нашей сети с функцией потерь и оптимизатором. Здесь мы используем sparse_categorical_crossentropy в качестве нашей функции потерь с помощью SGD в качестве нашего оптимизатора обучения.
from keras.optimizers import SGD
custom_face.compile(loss='sparse_categorical_crossentropy',
optimizer=SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
history = custom_face.fit_generator(
train_generator,
validation_data=valid_generator,
steps_per_epoch=49/batch_size,
validation_steps=valid_generator.n,
epochs=50)
custom_face.evaluate_generator(generator=valid_generator)
custom_face.save('vgg_face.h5')
Epoch 25/50
10/9 [==============================] - 60s 6s/step - loss: 1.4882 - acc: 0.8998 - val_loss: 1.5659 - val_acc: 0.5851
Epoch 26/50
10/9 [==============================] - 59s 6s/step - loss: 1.4882 - acc: 0.8998 - val_loss: 1.5638 - val_acc: 0.5809
Epoch 27/50
10/9 [==============================] - 60s 6s/step - loss: 1.4779 - acc: 0.8597 - val_loss: 1.5613 - val_acc: 0.5477
Epoch 28/50
10/9 [==============================] - 60s 6s/step - loss: 1.4755 - acc: 0.9199 - val_loss: 1.5576 - val_acc: 0.5809
Epoch 29/50
10/9 [==============================] - 60s 6s/step - loss: 1.4794 - acc: 0.9153 - val_loss: 1.5531 - val_acc: 0.5892
Epoch 30/50
10/9 [==============================] - 60s 6s/step - loss: 1.4714 - acc: 0.8953 - val_loss: 1.5510 - val_acc: 0.6017
Epoch 31/50
10/9 [==============================] - 60s 6s/step - loss: 1.4552 - acc: 0.9199 - val_loss: 1.5509 - val_acc: 0.5809
Epoch 32/50
10/9 [==============================] - 60s 6s/step - loss: 1.4504 - acc: 0.9199 - val_loss: 1.5492 - val_acc: 0.5975
Epoch 33/50
10/9 [==============================] - 60s 6s/step - loss: 1.4497 - acc: 0.8998 - val_loss: 1.5490 - val_acc: 0.5851
Epoch 34/50
10/9 [==============================] - 60s 6s/step - loss: 1.4453 - acc: 0.9399 - val_loss: 1.5529 - val_acc: 0.5643
Epoch 35/50
10/9 [==============================] - 60s 6s/step - loss: 1.4399 - acc: 0.9599 - val_loss: 1.5451 - val_acc: 0.5768
Epoch 36/50
10/9 [==============================] - 60s 6s/step - loss: 1.4373 - acc: 0.8998 - val_loss: 1.5424 - val_acc: 0.5768
Epoch 37/50
10/9 [==============================] - 60s 6s/step - loss: 1.4231 - acc: 0.9199 - val_loss: 1.5389 - val_acc: 0.6183
Epoch 38/50
10/9 [==============================] - 59s 6s/step - loss: 1.4247 - acc: 0.9199 - val_loss: 1.5372 - val_acc: 0.5934
Epoch 39/50
10/9 [==============================] - 60s 6s/step - loss: 1.4153 - acc: 0.9399 - val_loss: 1.5406 - val_acc: 0.5560
Epoch 40/50
10/9 [==============================] - 60s 6s/step - loss: 1.4074 - acc: 0.9800 - val_loss: 1.5327 - val_acc: 0.6224
Epoch 41/50
10/9 [==============================] - 60s 6s/step - loss: 1.4023 - acc: 0.9800 - val_loss: 1.5305 - val_acc: 0.6100
Epoch 42/50
10/9 [==============================] - 59s 6s/step - loss: 1.3938 - acc: 0.9800 - val_loss: 1.5269 - val_acc: 0.5975
Epoch 43/50
10/9 [==============================] - 60s 6s/step - loss: 1.3897 - acc: 0.9599 - val_loss: 1.5234 - val_acc: 0.6432
Epoch 44/50
10/9 [==============================] - 60s 6s/step - loss: 1.3828 - acc: 0.9800 - val_loss: 1.5210 - val_acc: 0.6556
Epoch 45/50
10/9 [==============================] - 59s 6s/step - loss: 1.3848 - acc: 0.9599 - val_loss: 1.5234 - val_acc: 0.5975
Epoch 46/50
10/9 [==============================] - 60s 6s/step - loss: 1.3716 - acc: 0.9800 - val_loss: 1.5216 - val_acc: 0.6432
Epoch 47/50
10/9 [==============================] - 60s 6s/step - loss: 1.3721 - acc: 0.9800 - val_loss: 1.5195 - val_acc: 0.6266
Epoch 48/50
10/9 [==============================] - 60s 6s/step - loss: 1.3622 - acc: 0.9599 - val_loss: 1.5108 - val_acc: 0.6141
Epoch 49/50
10/9 [==============================] - 60s 6s/step - loss: 1.3452 - acc: 0.9399 - val_loss: 1.5140 - val_acc: 0.6432
Epoch 50/50
10/9 [==============================] - 60s 6s/step - loss: 1.3387 - acc: 0.9599 - val_loss: 1.5100 - val_acc: 0.6266
Как видите, наша точность валидации составляет до 64%, это хороший результат для небольшого количества обучающих данных. Мы можем улучшить это, добавив больше слоев или добавив больше обучающих изображений, чтобы наша модель могла больше узнать о лицах и добиться большей точности.
Проверим нашу модель тестовой картинкой

from keras.models import load_model
from keras.preprocessing.image import load_img, save_img, img_to_array
from keras_vggface.utils import preprocess_input
test_img = image.load_img('test.jpg', target_size=(224, 224))
img_test = image.img_to_array(test_img)
img_test = np.expand_dims(img_test, axis=0)
img_test = utils.preprocess_input(img_test)
predictions = model.predict(img_test)
predicted_class=np.argmax(predictions,axis=1)
labels = (train_generator.class_indices)
labels = dict((v,k) for k,v in labels.items())
predictions = [labels[k] for k in predicted_class]
print(predictions)
['RobertDJr']
используя изображение Роберта Дауни-младшего в качестве нашего тестового изображения, оно показывает, что предсказанное лицо верно!
Прогноз с помощью Live Cam!
Как насчет того, чтобы проверить наши навыки, реализовав их с помощью веб-камеры? Используя OpenCV с каскадом Haar Face, чтобы найти наше лицо, и с помощью нашей сетевой модели мы можем распознать человека.
Первый шаг — подготовить лица вас и вашего друга. Чем больше у нас данных, тем лучше результат!
Подготовьте и обучите свою сеть, как на предыдущем шаге, после завершения обучения добавьте эту строку, чтобы получить входное изображение с камеры.
#Load trained model
from keras.models import load_model
from keras_vggface import utils
import cv2
image_size = 224
device_id = 0 #camera_device id
model = load_model('my faces.h5')
#make labels according to your dataset folder
labels = dict(fisrtname=0,secondname=1) #and so on
print(labels)
cascade_classifier = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
camera = cv2.VideoCapture(device_id)
while camera.isOpened():
ok, cam_frame = camera.read()
if not ok:
break
gray_img=cv2.cvtColor(cam_frame, cv2.COLOR_BGR2GRAY)
faces= cascade_classifier.detectMultiScale(gray_img, minNeighbors=5)
for (x,y,w,h) in faces:
cv2.rectangle(cam_frame,(x,y),(x+w,y+h),(255,255,0),2)
roi_color = cam_frame [y:y+h, x:x+w]
roi color = cv2.cvtColor(roi_color, cv2.COLOR_BGR2RGB)
roi_color = cv2.resize(roi_color, (image_size, image_size))
image = roi_color.astype(np.float32, copy=False)
image = np.expand_dims(image, axis=0)
image = preprocess_input(image, version=1) # or version=2
preds = model.predict(image)
predicted_class=np.argmax(preds,axis=1)
labels = dict((v,k) for k,v in labels.items())
name = [labels[k] for k in predicted_class]
cv2.putText(cam_frame,str(name),
(x + 10, y + 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,0,255), 2)
cv2.imshow('video image', cam_frame)
key = cv2.waitKey(30)
if key == 27: # press 'ESC' to quit
break
camera.release()
cv2.destroyAllWindows()
Какой из них лучше? Керас или Tensorflow
Keras предлагает простоту при написании сценария. Мы можем начать писать и понимать напрямую с Керасом, так как это не так уж сложно понять. Он более удобен для пользователя и прост в реализации, не нужно создавать много переменных для запуска модели. Таким образом, нам не нужно понимать каждую деталь внутреннего процесса.
С другой стороны, Tensorflow — это низкоуровневые операции, которые предлагают гибкость и расширенные операции, если вы хотите создать произвольный вычислительный график или модель. Tensorflow также может визуализировать процесс с помощью TensorBoard и специализированного инструмента отладчика.
Итак, если вы хотите начать работать с глубоким обучением без особых сложностей, используйте Keras. Потому что Keras предлагает простоту и удобство использования и простоту реализации, чем Tensorflow. Но если вы хотите написать свой собственный алгоритм в проекте глубокого обучения или исследовании, вам следует вместо этого использовать Tensorflow.
Резюме
Итак, давайте подытожим все, что мы обсудили и сделали в этом уроке.
- Keras в высокоуровневом API, который используется для упрощения сетей глубокого обучения с помощью внутреннего механизма.
- Keras прост в использовании и понимании благодаря поддержке Python, поэтому он кажется более естественным, чем когда-либо. Это хорошо для новичков, которые хотят узнать о глубоком обучении, и для исследователей, которым нужен простой в использовании API.
- Процесс установки прост, и вы можете использовать виртуальную среду или внешнюю платформу, такую как AWS.
- Keras также поставляется с различными сетевыми моделями, поэтому нам проще использовать доступную модель для предварительного обучения и точной настройки нашей собственной сетевой модели.
- Кроме того, есть много руководств и статей об использовании Keras из кодов сообществ по всему миру для целей глубокого обучения.
Статья является переводом guru99-com