Contents
Что такое линейная регрессия?
Линейная регрессия — это подход в статистике для моделирования отношений между двумя переменными. Это моделирование выполняется между скалярным откликом и одной или несколькими независимыми переменными. Связь с одной независимой переменной называется простой линейной регрессией, а для более чем одной независимой переменной — множественной линейной регрессией.
TensorFlow предоставляет инструменты для полного контроля над вычислениями. Это делается с помощью низкоуровневого API. Кроме того, TensorFlow оснащен широким набором API-интерфейсов для выполнения множества алгоритмов машинного обучения . Это высокоуровневый API. TensorFlow называет их оценщиками.
- Низкоуровневый API : построение архитектуры, оптимизация модели с нуля. Это сложно для новичка
- Высокоуровневый API : определите алгоритм. Это проще. TensorFlow предоставляет набор инструментов, называемый оценщиком , для построения, обучения, оценки и прогнозирования.
В этом уроке вы будете использовать только оценщики . Вычисления выполняются быстрее и проще в реализации. В первой части руководства объясняется, как использовать оптимизатор градиентного спуска для обучения линейной регрессии в TensorFlow. Во второй части вы будете использовать набор данных Boston для прогнозирования цены дома с помощью оценки TensorFlow
Как обучить модель линейной регрессии
Прежде чем мы начнем обучать модель, давайте посмотрим, что такое линейная регрессия.
Представьте, что у вас есть две переменные, x и y, и ваша задача состоит в том, чтобы предсказать ценность знания значения . Если вы нарисуете данные, вы увидите положительную связь между вашей независимой переменной x и вашей зависимой переменной y.

Вы можете заметить, что если x=1, y будет примерно равно 6, а если x=2, y будет около 8,5.
Это не очень точный метод и подвержен ошибкам, особенно при наборе данных с сотнями тысяч точек.
Линейная регрессия оценивается с помощью уравнения. Переменная y объясняется одной или многими ковариатами. В вашем примере есть только одна зависимая переменная. Если вам нужно написать это уравнение, оно будет:
![]()
С:
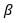 это предвзятость. т.е. если х=0, у=
это предвзятость. т.е. если х=0, у=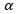 это вес, связанный с x
это вес, связанный с x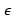 является невязкой или ошибкой модели. Он включает в себя то, что модель не может узнать из данных.
является невязкой или ошибкой модели. Он включает в себя то, что модель не может узнать из данных.
Представьте, что вы подходите под модель и находите следующее решение для:
- = 3,8
- = 2,78
Вы можете подставить эти числа в уравнение, и оно станет следующим:
у = 3,8 + 2,78х
Теперь у вас есть лучший способ найти значения для y. То есть вы можете заменить x любым значением, которое вы хотите предсказать y. На изображении ниже мы заменили x в уравнении всеми значениями в наборе данных и построили результат.

Красная линия представляет подобранное значение, то есть значения y для каждого значения x. Вам не нужно видеть значение x, чтобы предсказать y, для каждого x есть любое, которое принадлежит красной линии. Вы также можете предсказать значения x выше 2!
Если вы хотите расширить линейную регрессию на большее количество ковариатов, вы можете добавить в модель больше переменных. Разница между традиционным анализом и линейной регрессией заключается в том, что линейная регрессия смотрит на то, как y будет реагировать на каждую переменную x, взятую независимо.
Давайте посмотрим пример. Представьте, что вы хотите предсказать продажи магазина мороженого. Набор данных содержит различную информацию, такую как погода (т. е. дождливая, солнечная, облачная), информацию о клиентах (т. е. зарплата, пол, семейное положение).
Традиционный анализ попытается предсказать продажу, скажем, вычислив среднее значение для каждой переменной и попытавшись оценить продажу для различных сценариев. Это приведет к плохим прогнозам и ограничит анализ выбранным сценарием.
Если вы используете линейную регрессию, вы можете написать это уравнение:
![]()
Алгоритм найдет лучшее решение для весов; это означает, что он попытается минимизировать стоимость (разницу между построенной линией и точками данных).
Как работает алгоритм

Алгоритм будет выбирать случайное число для каждого![]() а также
а также![]() и замените значение x, чтобы получить предсказанное значение y. Если набор данных содержит 100 наблюдений, алгоритм вычисляет 100 прогнозируемых значений.
и замените значение x, чтобы получить предсказанное значение y. Если набор данных содержит 100 наблюдений, алгоритм вычисляет 100 прогнозируемых значений.
Мы можем вычислить ошибку, отмеченную![]() модели, которая представляет собой разницу между прогнозируемым значением и реальным значением. Положительная ошибка означает, что модель занижает прогноз y, а отрицательная ошибка означает, что модель завышает прогноз y.
модели, которая представляет собой разницу между прогнозируемым значением и реальным значением. Положительная ошибка означает, что модель занижает прогноз y, а отрицательная ошибка означает, что модель завышает прогноз y.
![]()
Ваша цель — минимизировать квадрат ошибки. Алгоритм вычисляет среднее значение квадрата ошибки. Этот шаг называется минимизацией ошибки. Для линейной регрессии используется среднеквадратическая ошибка , также называемая MSE. Математически это:

Где:
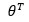 вес такой
вес такой относится к прогнозируемому значению
относится к прогнозируемому значению- у реальные значения
- m – количество наблюдений
Обратите внимание, что![]() означает, что он использует транспонирование матриц.
означает, что он использует транспонирование матриц. ![]() является математической записью среднего.
является математической записью среднего.
Цель состоит в том, чтобы найти лучшее![]() которые минимизируют MSE
которые минимизируют MSE
Если средняя ошибка велика, это означает, что модель работает плохо и веса выбраны неправильно. Для коррекции весов нужно использовать оптимизатор. Традиционный оптимизатор называется Gradient Descent .
Градиентный спуск берет производную и уменьшает или увеличивает вес. Если производная положительна, вес уменьшается. Если производная отрицательна, вес увеличивается. Модель обновит веса и пересчитает ошибку. Этот процесс повторяется до тех пор, пока ошибка больше не изменится. Каждый процесс называется итерацией . Кроме того, градиенты умножаются на скорость обучения. Это указывает на скорость обучения.
Если скорость обучения слишком мала, для сходимости алгоритма потребуется очень много времени (т.е. потребуется много итераций). Если скорость обучения слишком высока, алгоритм может никогда не сойтись.

Как видно из рисунка выше, модель повторяет процесс примерно 20 раз, прежде чем найти стабильное значение для весов, что приводит к наименьшей ошибке.
Обратите внимание, что , что ошибка не равна нулю, а стабилизируется около 5. Это означает, что модель делает типичную ошибку 5. Если вы хотите уменьшить ошибку, вам нужно добавить в модель больше информации, например, больше переменных или использовать разные оценщики.
Вы помните первое уравнение
![]()
Окончательные веса 3,8 и 2,78. В видео ниже показано, как градиентный спуск оптимизирует функцию потерь, чтобы найти эти веса.
Как обучить линейную регрессию с помощью TensorFlow
Теперь, когда вы лучше понимаете, что происходит за капотом, вы готовы использовать API-интерфейс оценки, предоставляемый TensorFlow, для обучения вашей первой линейной регрессии с использованием TensorFlow.
Вы будете использовать набор данных Boston, который включает следующие переменные.
| крим | уровень преступности на душу населения по городам |
|---|---|
| зн | доля земель под жилую застройку зонирована под участки площадью более 25 000 кв. футов. |
| Инд | доля акров неторгового бизнеса на город. |
| нокс | концентрация оксидов азота |
| г.м. | среднее количество комнат в квартире |
| возраст | доля жилых единиц, построенных до 1940 г. |
| дис | взвешенные расстояния до пяти центров занятости Бостона |
| налог | Полная ставка налога на имущество за доллары 10 000 |
| ptratio | соотношение учеников и учителей по городам |
| медв | Средняя стоимость домов, занимаемых владельцами, в тысячах долларов |
Вы создадите три разных набора данных:
| набор данных | задача | форма |
|---|---|---|
| Подготовка | Обучите модель и получите веса | 400, 10 |
| Оценка | Оцените производительность модели на невидимых данных | 100, 10 |
| Предсказывать | Используйте модель для прогнозирования стоимости дома на основе новых данных. | 6, 10 |
Цель состоит в том, чтобы использовать особенности набора данных для прогнозирования стоимости дома.
Во второй части руководства вы узнаете, как использовать TensorFlow с тремя различными способами импорта данных:
- С пандами
- С Нампи
- Только ТФ
Обратите внимание, что все варианты дают одинаковые результаты.
Вы узнаете, как использовать высокоуровневый API для построения, обучения и оценки модели линейной регрессии TensorFlow. Если вы использовали низкоуровневый API, вам нужно было вручную определить:
- Функция потерь
- Оптимизация: градиентный спуск
- Умножение матриц
- График и тензор
Это утомительно и более сложно для новичка.
Панды
Вам нужно импортировать необходимые библиотеки для обучения модели.
import pandas as pd from sklearn import datasets import tensorflow as tf import itertools
Шаг 1) Импортируйте данные с помощью panda .
Вы определяете имена столбцов и сохраняете их в COLUMNS. Вы можете использовать pd.read_csv() для импорта данных.
COLUMNS = ["crim", "zn", "indus", "nox", "rm", "age",
"dis", "tax", "ptratio", "medv"]
training_set = pd.read_csv(“E:/boston_train.csv”, skipinitialspace=True, skiprows=1, имена=СТОЛБЦЫ)
test_set = pd.read_csv(“E:/boston_test.csv”, skipinitialspace=True, skiprows=1, имена=СТОЛБЦЫ)
Prediction_set = pd.read_csv(“E:/boston_predict.csv”, skipinitialspace=True, skiprows=1, имена=COLUMNS)
Вы можете распечатать форму данных.
print(training_set.shape, test_set.shape, prediction_set.shape)
Выход
(400, 10) (100, 10) (6, 10)
Обратите внимание, что метка, т. е. ваш y, включена в набор данных. Поэтому вам нужно определить два других списка. Один содержит только функции, а другой – только имя метки. Эти два списка сообщат вашему оценщику, какие функции есть в наборе данных и какое имя столбца является меткой.
Это делается с помощью кода ниже.
FEATURES = ["crim", "zn", "indus", "nox", "rm",
"age", "dis", "tax", "ptratio"]
LABEL = "medv"
Шаг 2) Преобразование данных
Вам необходимо преобразовать числовые переменные в правильный формат. Tensorflow предоставляет метод для преобразования непрерывной переменной: tf.feature_column.numeric_column().
На предыдущем шаге вы определяете список функций, которые хотите включить в модель. Теперь вы можете использовать этот список для преобразования их в числовые данные. Если вы хотите исключить функции из своей модели, не стесняйтесь удалять одну или несколько переменных в списке FEATURES, прежде чем создавать feature_cols.
Обратите внимание, что вы будете использовать понимание списка Python со списком FEATURES для создания нового списка с именем feature_cols. Это поможет вам не писать девять раз tf.feature_column.numeric_column(). Понимание списков — это более быстрый и чистый способ создания новых списков.
feature_cols = [tf.feature_column.numeric_column(k) for k in FEATURES]
Шаг 3) Определите оценщик
На этом шаге вам нужно определить оценщик. В настоящее время Tensorflow предоставляет 6 встроенных оценщиков, в том числе 3 для задачи классификации и 3 для задачи регрессии TensorFlow:
- регрессор
- DNNРегрессор
- Линейный регрессор
- DNNLineaCombinedRegressor
- Классификатор
- DNNКлассификатор
- Линейный классификатор
- DNNLineaCombinedClassifier
В этом уроке вы будете использовать линейный регрессор. Чтобы получить доступ к этой функции, вам нужно использовать tf.estimator.
Функция требует два аргумента:
- feature_columns: содержит переменные для включения в модель.
- model_dir: путь для хранения графика, сохранения параметров модели и т. д.
Tensorflow автоматически создаст файл с именем train в вашем рабочем каталоге. Вам нужно использовать этот путь для доступа к Tensorboard, как показано в приведенном ниже примере регрессии TensorFlow
estimator = tf.estimator.LinearRegressor(
feature_columns=feature_cols,
model_dir="train")
Выход
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_model_dir': 'train', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps':
None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute':
None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1a215dc550>, '_task_type':
'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
Сложная часть TensorFlow — это способ подачи модели. Tensorflow предназначен для работы с параллельными вычислениями и очень большими наборами данных. Из-за ограниченности машинных ресурсов невозможно загрузить в модель все данные сразу. Для этого вам нужно каждый раз передавать пакет данных. Обратите внимание, что речь идет об огромном наборе данных с миллионами и более записей. Если вы не добавите пакет, вы получите ошибку памяти.
Например, если ваши данные содержат 100 наблюдений и вы определяете размер пакета 10, это означает, что модель будет видеть 10 наблюдений для каждой итерации (10*10).
Когда модель просмотрела все данные, она заканчивает одну эпоху . Эпоха определяет, сколько раз вы хотите, чтобы модель видела данные. Лучше установить для этого шага значение none и позволить модели выполнять итерацию определенное количество раз.
Вторая информация, которую нужно добавить, — если вы хотите перетасовать данные перед каждой итерацией. Во время обучения важно перемешивать данные, чтобы модель не усвоила конкретный шаблон набора данных. Если модель узнает подробности лежащего в основе шаблона данных, ей будет трудно обобщить прогноз для невидимых данных. Это называется переоснащением . Модель хорошо работает с обучающими данными, но не может правильно прогнозировать невидимые данные.
TensorFlow упрощает выполнение этих двух шагов. Когда данные поступают в конвейер, он знает, сколько наблюдений ему нужно (пакетных) и нужно ли перемешивать данные.
Чтобы указать Tensorflow, как кормить модель, вы можете использовать pandas_input_fn. Этому объекту нужно 5 параметров:
- х: данные функции
- у: данные метки
- размер_пакета: пакет. По умолчанию 128
- num_epoch: количество эпох, по умолчанию 1
- shuffle: перемешивать или нет данные. По умолчанию Нет
Вам нужно много раз передать модель, поэтому вы определяете функцию для повторения этого процесса. все это функция get_input_fn.
def get_input_fn(data_set, num_epochs=None, n_batch = 128, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({k: data_set[k].values for k in FEATURES}),
y = pd.Series(data_set[LABEL].values),
batch_size=n_batch,
num_epochs=num_epochs,
shuffle=shuffle)
Обычный метод оценки производительности модели заключается в следующем:
- Обучите модель
- Оцените модель в другом наборе данных
- Сделать прогноз
Оценщик Tensorflow предоставляет три различные функции для простого выполнения этих трех шагов.
Шаг 4) : Обучите модель
Вы можете использовать поезд оценщика, чтобы оценить модель. Для оценки поезда требуется input_fn и несколько шагов. Вы можете использовать функцию, которую вы создали выше, чтобы накормить модель. Затем вы указываете модели повторить 1000 раз. Обратите внимание, что вы не указываете количество эпох, вы позволяете модели повторяться 1000 раз. Если вы установите число эпох равным 1, то модель будет повторяться 4 раза: в обучающем наборе 400 записей, а размер пакета равен 128.
- 128 строк
- 128 строк
- 128 строк
- 16 рядов
Поэтому проще установить число эпох равным нулю и определить количество итераций, как показано в приведенном ниже примере классификации TensorFlow.
estimator.train(input_fn=get_input_fn(training_set,
num_epochs=None,
n_batch = 128,
shuffle=False),
steps=1000)
Выход
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into train/model.ckpt. INFO:tensorflow:loss = 83729.64, step = 1 INFO:tensorflow:global_step/sec: 238.616 INFO:tensorflow:loss = 13909.657, step = 101 (0.420 sec) INFO:tensorflow:global_step/sec: 314.293 INFO:tensorflow:loss = 12881.449, step = 201 (0.320 sec) INFO:tensorflow:global_step/sec: 303.863 INFO:tensorflow:loss = 12391.541, step = 301 (0.327 sec) INFO:tensorflow:global_step/sec: 308.782 INFO:tensorflow:loss = 12050.5625, step = 401 (0.326 sec) INFO:tensorflow:global_step/sec: 244.969 INFO:tensorflow:loss = 11766.134, step = 501 (0.407 sec) INFO:tensorflow:global_step/sec: 155.966 INFO:tensorflow:loss = 11509.922, step = 601 (0.641 sec) INFO:tensorflow:global_step/sec: 263.256 INFO:tensorflow:loss = 11272.889, step = 701 (0.379 sec) INFO:tensorflow:global_step/sec: 254.112 INFO:tensorflow:loss = 11051.9795, step = 801 (0.396 sec) INFO:tensorflow:global_step/sec: 292.405 INFO:tensorflow:loss = 10845.855, step = 901 (0.341 sec) INFO:tensorflow:Saving checkpoints for 1000 into train/model.ckpt. INFO:tensorflow:Loss for final step: 5925.9873. Вы можете проверить Tensorboard с помощью следующей команды:
activate hello-tf # For MacOS tensorboard --logdir=./train # For Windows tensorboard --logdir=train
Шаг 5) Оцените свою модель
Вы можете оценить соответствие вашей модели тестовому набору с помощью приведенного ниже кода:
ev = estimator.evaluate(
input_fn=get_input_fn(test_set,
num_epochs=1,
n_batch = 128,
shuffle=False))
Выход
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2018-05-13-01:43:13 INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from train/model.ckpt-1000 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Finished evaluation at 2018-05-13-01:43:13 INFO:tensorflow:Saving dict for global step 1000: average_loss = 32.15896, global_step = 1000, loss = 3215.896 Вы можете распечатать потери с кодом ниже:
loss_score = ev["loss"]
print("Loss: {0:f}".format(loss_score))
Выход
Loss: 3215.895996
Модель имеет потери 3215. Вы можете проверить сводную статистику, чтобы понять, насколько велика ошибка.
training_set['medv'].describe()
Выход
count 400.000000 mean 22.625500 std 9.572593 min 5.000000 25% 16.600000 50% 21.400000 75% 25.025000 max 50.000000 Name: medv, dtype: float64
Из приведенной выше сводной статистики вы знаете, что средняя цена дома составляет 22 тысячи, при минимальной цене 9 тысяч и максимальной 50 тысяч. Модель допускает типичную ошибку в 3к долларов.
Шаг 6) Сделайте прогноз
Наконец, вы можете использовать прогноз TensorFlow для оценки стоимости 6 домов в Бостоне.
y = estimator.predict(
input_fn=get_input_fn(prediction_set,
num_epochs=1,
n_batch = 128,
shuffle=False))
Чтобы напечатать оценочные значения , вы можете использовать этот код:
predictions = list(p["predictions"] for p in itertools.islice(y, 6))print("Predictions: {}".format(str(predictions)))
Выход
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from train/model.ckpt-1000 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. Predictions: [array([32.297546], dtype=float32), array([18.96125], dtype=float32), array([27.270979], dtype=float32), array([29.299236], dtype=float32), array([16.436684], dtype=float32), array([21.460876], dtype=float32)]
Модель прогнозирует следующие значения:
| Дом | Прогноз | |
|---|---|---|
| 1 | 32.29 | |
| 2 | 18,96 | |
| 3 | 27.27 | |
| 4 | 29.29 | |
| 5 | 16.43 | |
| 7 | 21.46 |
Обратите внимание, что мы не знаем истинного значения . В учебнике по глубокому обучению вы попытаетесь превзойти линейную модель.
тупое решение
В этом разделе объясняется, как обучить модель с помощью оценщика numpy для подачи данных. Метод тот же, за исключением того, что вы будете использовать оценщик numpy_input_fn.
training_set_n = pd.read_csv(“E:/boston_train.csv”).values
test_set_n = pd.read_csv(“E:/boston_test.csv”).значения
Prediction_set_n = pd.read_csv(“E:/boston_predict.csv”).values
Шаг 1) Импорт данных
Прежде всего, вам нужно отличить переменные функции от метки. Вы должны сделать это для обучающих данных и оценки. Быстрее определить функцию для разделения данных.
def prepare_data(df):
X_train = df[:, :-3]
y_train = df[:,-3]
return X_train, y_train
Вы можете использовать функцию, чтобы отделить метку от функций набора данных обучения/оценки.
X_train, y_train = prepare_data (training_set_n) X_test, y_test = prepare_data(test_set_n)
Вам нужно исключить последний столбец набора данных прогнозирования, поскольку он содержит только NaN
x_predict = prediction_set_n[:, :-2]
Подтвердите форму массива. Обратите внимание, что метка не должна иметь размера, это означает (400,).
print(X_train.shape, y_train.shape, x_predict.shape)
Выход
(400, 9) (400,) (6, 9)
Вы можете построить столбцы функций следующим образом:
feature_columns = [tf.feature_column.numeric_column('x', shape=X_train.shape[1:])]
Оценщик определяется, как и раньше, вы указываете столбцы функций и место сохранения графика.
estimator = tf.estimator.LinearRegressor(
feature_columns=feature_columns,
model_dir="train1")
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_model_dir': 'train1', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps':
None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours':
10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec':
<tensorflow.python.training.server_lib.ClusterSpec object at 0x1a218d8f28>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster':
0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
Вы можете использовать numpy estimapor для подачи данных в модель, а затем обучить модель. Обратите внимание, что мы определяем функцию input_fn перед тем, как упростить чтение.
# Train the estimatortrain_input = tf.estimator.inputs.numpy_input_fn(
x={"x": X_train},
y=y_train,
batch_size=128,
shuffle=False,
num_epochs=None)
estimator.train(input_fn = train_input,steps=5000)
Выход
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into train1/model.ckpt. INFO:tensorflow:loss = 83729.64, step = 1 INFO:tensorflow:global_step/sec: 490.057 INFO:tensorflow:loss = 13909.656, step = 101 (0.206 sec) INFO:tensorflow:global_step/sec: 788.986 INFO:tensorflow:loss = 12881.45, step = 201 (0.126 sec) INFO:tensorflow:global_step/sec: 736.339 INFO:tensorflow:loss = 12391.541, step = 301 (0.136 sec) INFO:tensorflow:global_step/sec: 383.305 INFO:tensorflow:loss = 12050.561, step = 401 (0.260 sec) INFO:tensorflow:global_step/sec: 859.832 INFO:tensorflow:loss = 11766.133, step = 501 (0.117 sec) INFO:tensorflow:global_step/sec: 804.394 INFO:tensorflow:loss = 11509.918, step = 601 (0.125 sec) INFO:tensorflow:global_step/sec: 753.059 INFO:tensorflow:loss = 11272.891, step = 701 (0.134 sec) INFO:tensorflow:global_step/sec: 402.165 INFO:tensorflow:loss = 11051.979, step = 801 (0.248 sec) INFO:tensorflow:global_step/sec: 344.022 INFO:tensorflow:loss = 10845.854, step = 901 (0.288 sec) INFO:tensorflow:Saving checkpoints for 1000 into train1/model.ckpt. INFO:tensorflow:Loss for final step: 5925.985. Out[23]: <tensorflow.python.estimator.canned.linear.LinearRegressor at 0x1a1b6ea860> Вы повторяете тот же шаг с другим оценщиком, чтобы оценить свою модель.
eval_input = tf.estimator.inputs.numpy_input_fn(
x={"x": X_test},
y=y_test,
shuffle=False,
batch_size=128,
num_epochs=1)
estimator.evaluate(eval_input,steps=None)
Выход
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-05-13-01:44:00
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from train1/model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Finished evaluation at 2018-05-13-01:44:00
INFO:tensorflow:Saving dict for global step 1000: average_loss = 32.158947, global_step = 1000, loss = 3215.8945
Out[24]:
{'average_loss': 32.158947, 'global_step': 1000, 'loss': 3215.8945}
Наконец, вы можете вычислить прогноз. Это должно быть похоже на панд.
test_input = tf.estimator.inputs.numpy_input_fn(
x={"x": x_predict},
batch_size=128,
num_epochs=1,
shuffle=False)
y = estimator.predict(test_input)
predictions = list(p["predictions"] for p in itertools.islice(y, 6))
print("Predictions: {}".format(str(predictions)))
Выход
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from train1/model.ckpt-1000 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. Predictions: [array([32.297546], dtype=float32), array([18.961248], dtype=float32), array([27.270979], dtype=float32), array([29.299242], dtype=float32), array([16.43668], dtype=float32), array([21.460878], dtype=float32)]
Тензорное решение
Последний раздел посвящен решению TensorFlow. Этот метод немного сложнее, чем предыдущий.
Обратите внимание, что если вы используете блокнот Jupyter, вам необходимо перезапустить и очистить ядро, чтобы запустить этот сеанс.
TensorFlow создал отличный инструмент для передачи данных в конвейер. В этом разделе вы сами создадите функцию input_fn.
Шаг 1) Определите путь и формат данных
Прежде всего, вы объявляете две переменные с путем к CSV-файлу. Обратите внимание, что у вас есть два файла: один для обучающего набора, а другой для тестового набора.
import tensorflow as tf
df_train = "E:/boston_train.csv"
df_eval = "E:/boston_test.csv"
Затем вам нужно определить столбцы, которые вы хотите использовать, из CSV-файла. Мы будем использовать все. После этого вам нужно объявить тип переменной.
Переменная с плавающей запятой определяется [0.]
COLUMNS = ["crim", "zn", "indus", "nox", "rm", "age",
"dis", "tax", "ptratio", "medv"]RECORDS_ALL = [[0.0], [0.0], [0.0], [0.0],[0.0],[0.0],[0.0],[0.0],[0.0],[0.0]]
Шаг 2) Определите функцию input_fn
Функцию можно разбить на три части:
- Импорт данных
- Создайте итератор
- Потребляйте данные
Ниже приведен общий код для определения функции. Код будет объяснен после
def input_fn(data_file, batch_size, num_epoch = None):
# Step 1
def parse_csv(value):
columns = tf.decode_csv(value, record_defaults= RECORDS_ALL)
features = dict(zip(COLUMNS, columns))
#labels = features.pop('median_house_value')
labels = features.pop('medv')
return features, labels
# Extract lines from input files using the
Dataset API. dataset = (tf.data.TextLineDataset(data_file) # Read text file
.skip(1) # Skip header row
.map(parse_csv))
dataset = dataset.repeat(num_epoch)
dataset = dataset.batch(batch_size)
# Step 3
iterator = dataset.make_one_shot_iterator()
features, labels = iterator.get_next()
return features, labels
** Импорт данных**
Для CSV-файла метод набора данных считывает по одной строке за раз. Чтобы построить набор данных, вам нужно использовать объект TextLineDataset. У вашего набора данных есть заголовок, поэтому вам нужно использовать skip(1), чтобы пропустить первую строку. На этом этапе вы только читаете данные и исключаете заголовок из конвейера. Чтобы скормить модель, вам нужно отделить функции от этикетки. Метод, используемый для применения любого преобразования к данным, называется картой.
Этот метод вызывает функцию, которую вы создадите, чтобы указать, как преобразовывать данные. В двух словах, вам нужно передать данные в объекте TextLineDataset, исключить заголовок и применить преобразование, указанное функцией. Объяснение кода
- tf.data.TextLineDataset(data_file): эта строка считывает CSV-файл.
- .skip(1) : пропустить заголовок
- .map(parse_csv)): разобрать записи на тензоры. Вам нужно определить функцию для указания объекта карты. Вы можете вызвать эту функцию parse_csv.
Эта функция анализирует файл csv с помощью метода tf.decode_csv и объявляет функции и метку. Функции могут быть объявлены как словарь или кортеж. Вы используете метод словаря, потому что это более удобно. Объяснение кода
- tf.decode_csv(value, record_defaults= RECORDS_ALL): метод decode_csv использует выходные данные TextLineDataset для чтения CSV-файла. record_defaults сообщает TensorFlow о типе столбцов.
- dict(zip(_CSV_COLUMNS, columns)): заполнить словарь всеми столбцами, извлеченными во время этой обработки данных.
- features.pop(‘median_house_value’): Исключить целевую переменную из переменной функции и создать переменную метки.
Набору данных нужны дополнительные элементы для итеративной подачи тензоров. Действительно, вам нужно добавить метод repeat, чтобы позволить набору данных бесконечно продолжать подавать модель. Если вы не добавите метод, модель выполнит итерацию только один раз, а затем выдаст ошибку, поскольку в конвейер больше не поступают данные.
После этого вы можете контролировать размер партии с помощью пакетного метода. Это означает, что вы указываете набору данных, сколько данных вы хотите передать в конвейер для каждой итерации. Если вы установите большой размер пакета, модель будет работать медленно.
Шаг 3) Создайте итератор
Теперь вы готовы ко второму шагу: создайте итератор для возврата элементов в наборе данных.
Самый простой способ создать оператор — использовать метод make_one_shot_iterator.
После этого вы можете создавать функции и метки из итератора.
Шаг 4) Использование данных
Вы можете проверить, что происходит с функцией input_fn. Вам нужно вызвать функцию в сеансе, чтобы использовать данные. Вы пытаетесь с размером партии, равным 1.
Обратите внимание, что он печатает функции в словаре и метку в виде массива.
Он покажет первую строку файла csv. Вы можете попытаться запустить этот код много раз с разным размером пакета.
next_batch = input_fn(df_train, batch_size = 1, num_epoch = None)
with tf.Session() as sess:
first_batch = sess.run(next_batch)
print(first_batch)
Выход
({'crim': array([2.3004], dtype=float32), 'zn': array([0.], dtype=float32), 'indus': array([19.58], dtype=float32), 'nox':
array([0.605], dtype=float32), 'rm': array([6.319], dtype=float32), 'age': array([96.1], dtype=float32), 'dis': array([2.1], dtype=float32), 'tax':
array([403.], dtype=float32), 'ptratio': array([14.7], dtype=float32)}, array([23.8], dtype=float32))
Шаг 4) Определите столбец функций
Вам нужно определить числовые столбцы следующим образом:
X1= tf.feature_column.numeric_column('crim')
X2= tf.feature_column.numeric_column('zn')
X3= tf.feature_column.numeric_column('indus')
X4= tf.feature_column.numeric_column('nox')
X5= tf.feature_column.numeric_column('rm')
X6= tf.feature_column.numeric_column('age')
X7= tf.feature_column.numeric_column('dis')
X8= tf.feature_column.numeric_column('tax')
X9= tf.feature_column.numeric_column('ptratio')
Обратите внимание, что вам нужно объединить все переменные в ведро
base_columns = [X1, X2, X3, X4, X5, X6, X7, X8, X9]
Шаг 5) Постройте модель
Вы можете обучить модель с помощью оценщика LinearRegressor.
model = tf.estimator.LinearRegressor(feature_columns=base_columns, model_dir='train3')
Выход
INFO:tensorflow:Using default config. INFO:tensorflow:Using config: {'_model_dir': 'train3', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps':
None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute':
None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1820a010f0>, '_task_type': 'worker', '_task_id':
0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
Вам нужно использовать лямбда-функцию, чтобы разрешить запись аргумента в функцию inpu_fn. Если вы не используете лямбда-функцию, вы не можете обучить модель.
# Train the estimatormodel.train(steps =1000,
input_fn= lambda : input_fn(df_train,batch_size=128, num_epoch = None))
Выход
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into train3/model.ckpt. INFO:tensorflow:loss = 83729.64, step = 1 INFO:tensorflow:global_step/sec: 72.5646 INFO:tensorflow:loss = 13909.657, step = 101 (1.380 sec) INFO:tensorflow:global_step/sec: 101.355 INFO:tensorflow:loss = 12881.449, step = 201 (0.986 sec) INFO:tensorflow:global_step/sec: 109.293 INFO:tensorflow:loss = 12391.541, step = 301 (0.915 sec) INFO:tensorflow:global_step/sec: 102.235 INFO:tensorflow:loss = 12050.5625, step = 401 (0.978 sec) INFO:tensorflow:global_step/sec: 104.656 INFO:tensorflow:loss = 11766.134, step = 501 (0.956 sec) INFO:tensorflow:global_step/sec: 106.697 INFO:tensorflow:loss = 11509.922, step = 601 (0.938 sec) INFO:tensorflow:global_step/sec: 118.454 INFO:tensorflow:loss = 11272.889, step = 701 (0.844 sec) INFO:tensorflow:global_step/sec: 114.947 INFO:tensorflow:loss = 11051.9795, step = 801 (0.870 sec) INFO:tensorflow:global_step/sec: 111.484 INFO:tensorflow:loss = 10845.855, step = 901 (0.897 sec) INFO:tensorflow:Saving checkpoints for 1000 into train3/model.ckpt. INFO:tensorflow:Loss for final step: 5925.9873. Out[8]: <tensorflow.python.estimator.canned.linear.LinearRegressor at 0x18225eb8d0> Вы можете оценить соответствие вашей модели тестовому набору с помощью кода ниже:
results = model.evaluate(steps =None,input_fn=lambda: input_fn(df_eval, batch_size =128, num_epoch = 1))
for key in results:
print(" {}, was: {}".format(key, results[key])
Выход
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2018-05-13-02:06:02 INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from train3/model.ckpt-1000 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Finished evaluation at 2018-05-13-02:06:02 INFO:tensorflow:Saving dict for global step 1000: average_loss = 32.15896, global_step = 1000, loss = 3215.896 average_loss, was: 32.158958435058594 loss, was: 3215.89599609375 global_step, was: 1000
Последним шагом является прогнозирование значения на основе значения матрицы признаков. Вы можете написать словарь со значениями, которые хотите предсказать. Ваша модель имеет 9 функций, поэтому вам нужно указать значение для каждой. Модель даст прогноз для каждого из них.
В приведенном ниже коде вы записали значения каждой функции, содержащейся в CSV-файле df_predict.
Вам нужно написать новую функцию input_fn, потому что в наборе данных нет метки. Вы можете использовать API from_tensor из набора данных.
prediction_input = {
'crim': [0.03359,5.09017,0.12650,0.05515,8.15174,0.24522],
'zn': [75.0,0.0,25.0,33.0,0.0,0.0],
'indus': [2.95,18.10,5.13,2.18,18.10,9.90],
'nox': [0.428,0.713,0.453,0.472,0.700,0.544],
'rm': [7.024,6.297,6.762,7.236,5.390,5.782],
'age': [15.8,91.8,43.4,41.1,98.9,71.7],
'dis': [5.4011,2.3682,7.9809,4.0220,1.7281,4.0317],
'tax': [252,666,284,222,666,304],
'ptratio': [18.3,20.2,19.7,18.4,20.2,18.4]
}
def test_input_fn():
dataset = tf.data.Dataset.from_tensors(prediction_input)
return dataset
# Predict all our prediction_inputpred_results = model.predict(input_fn=test_input_fn)
Наконец, вы печатаете прогнозы.
for pred in enumerate(pred_results): print(pred)
Выход
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from train3/model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
(0, {'predictions': array([32.297546], dtype=float32)})
(1, {'predictions': array([18.96125], dtype=float32)})
(2, {'predictions': array([27.270979], dtype=float32)})
(3, {'predictions': array([29.299236], dtype=float32)})
(4, {'predictions': array([16.436684], dtype=float32)})
(5, {'predictions': array([21.460876], dtype=float32)})
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from train3/model.ckpt-5000 INFO:
tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. (0, {'predictions': array([35.60663], dtype=float32)}) (1, {'predictions': array([22.298521],
dtype=float32)}) (2, {'predictions': array([25.74533], dtype=float32)}) (3, {'predictions': array([35.126694], dtype=float32)}) (4, {'predictions': array([17.94416], dtype=float32)})
(5, {'predictions': array([22.606628], dtype=float32)})
Резюме
Для обучения модели необходимо:
- Определите функции: Независимые переменные: X
- Определите метку: Зависимая переменная: y
- Построить поезд/тестовый набор
- Определить начальный вес
- Определите функцию потерь: MSE
- Оптимизация модели: градиентный спуск
- Определять:
- Скорость обучения
- Номер эпохи
- Размер партии
В этом руководстве вы узнали, как использовать высокоуровневый API для оценки TensorFlow линейной регрессии. Вам необходимо определить:
- Колонки признаков. Если непрерывно: tf.feature_column.numeric_column(). Вы можете заполнить список пониманием списка python
- Оценщик: tf.estimator.LinearRegressor(feature_columns, model_dir)
- Функция для импорта данных, размера пакета и эпохи: input_fn()
После этого вы готовы тренироваться, оценивать и делать прогнозы с помощью train(), Assessment() и Predict().
Статья является переводом guru99.com